微拍堂深度召回在文玩个性化推荐中的实践

分享嘉宾:赵争超 前微拍堂算法负责人
编辑整理:王岩
出品平台:DataFunTalk
导读: 当前阶段,“个性化推荐”早已成为了电商平台的基建工程,也是AI驱动业务增长的重要支撑,概括地说,个性化推荐是一门AI结合消费者行为心理学,运筹优化等多个领域的交叉学科。而今天的分享,是我们对“个性化推荐”这个命题在文玩拍卖行业的一次实践总结和深入思考,受限于篇幅,本文会聚焦在推荐的召回侧,也就是matching阶段的深度学习实践。具体内容包括:
- 业务背景及技术挑战
- 解决方案综述
- 拍品embedding学习
- 跨域学习搜索关键词意图embedding
- 用户多兴趣embedding学习
- 总结与展望
01 业务背景及技术挑战
1. 微拍堂APP个性化推荐业务场景
微拍堂是一家文玩行业的垂直电商,专注在中国传统文化相关的细分市场,我们把线下竞拍的交易模式搬到了线上。消费者可以对拍品出价,也可以与他人竞价,最终价高者得。在微拍堂APP上,涉及到个性化的场景主要有首页/频道页的feed流,以及购物路径节点上的内容推荐。推荐算法在APP流量的个性化分发以及用户体验上起着非常核心的作用。
2. 召回侧的技术挑战
在文玩行业的细分市场,在拍卖的交易模式下,对比综合性电商,个性化推荐(特别是召回阶段),有着独特的技术挑战:
- 拍品内容理解:在文玩行业,缺少综合电商成熟的结构化类目体系,缺少商品卖点的标准表达模板。而且在竞拍的模式下,每个拍品都相当于秒杀商品(浅库存、短生命周期),我们很难利用历史信息直接去训练item embedding。
- 文玩购物决策的业务理解难度:文玩行业的知识门槛下,用户的专业性差异大,行为上对需求的表达不太明确,训练出来的user embedding质量在人群之间的差异比较大。
- 大部分用户在文玩行业的需求过于聚焦,也给推荐内容的多样性带来比较大的挑战。
- 通过深度召回学习到用户的多兴趣向量之后,如何‘带约束’地去召回最近邻(只在某个细分的类目里面去召回用户偏好拍品),也是一个需要解决的技术问题。
02 整体技术方案
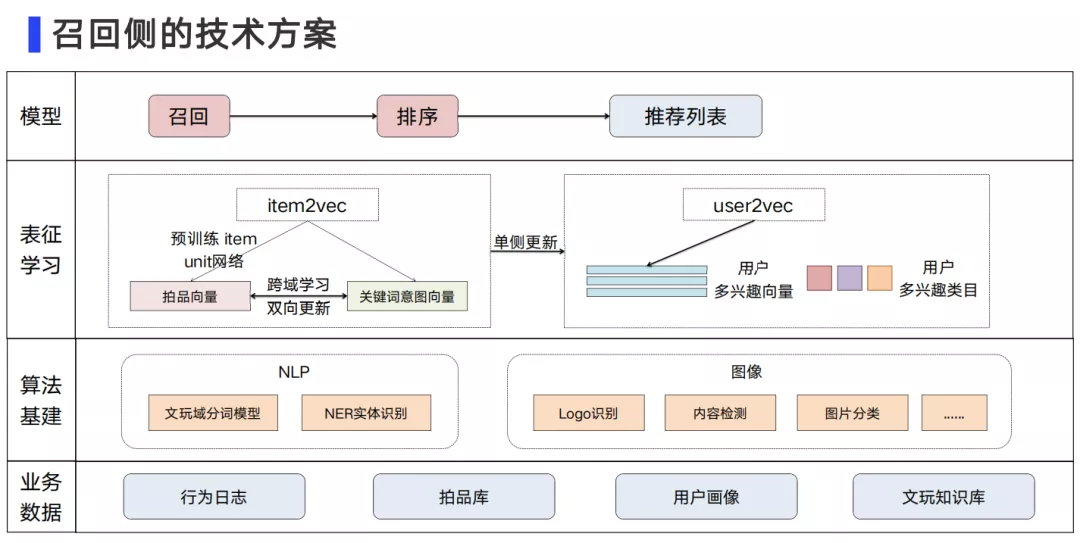
针对拍品的属性,类目体系缺失的问题,我们投入了很多精力在NLP和图像算法,来作为推荐的算法基建工作。
- 在NLP部分:我们构建了文玩领域的分词模型,解决文玩专有名词的识别问题。同时,也把更大的精力放在了NER上,通过实体识别,在非结构化商品内容描述里挖掘更多的卖点,比如,翡翠的产地、产状、题材、寓意等。
- 在图像算法部分:我们通过识别商品主图中的关键图像特征,挖掘反映拍品的价值以及确定性的相关信息(如,钱币的年代等)。通过这两部分的算法基建工作,我们挖掘了上千个标签,为后续的召回算法提供了大量的基础特征。
在召回侧的表征学习上,我们重点解决了三个问题:
- 通过预训练的item-unit学习拍品的embedding向量表达。
- 通过跨域学习将拍品embedding通过DSSM迁移到搜索关键词,来表达用户的搜索意图。
- 通过构建user多峰兴趣模型将item的embedding迁移到user的embedding,挖掘用户在时间跨度上的长期和短期行为,融合用户多兴趣向量。
03 拍品embedding学习
1. 拍品embedding学习
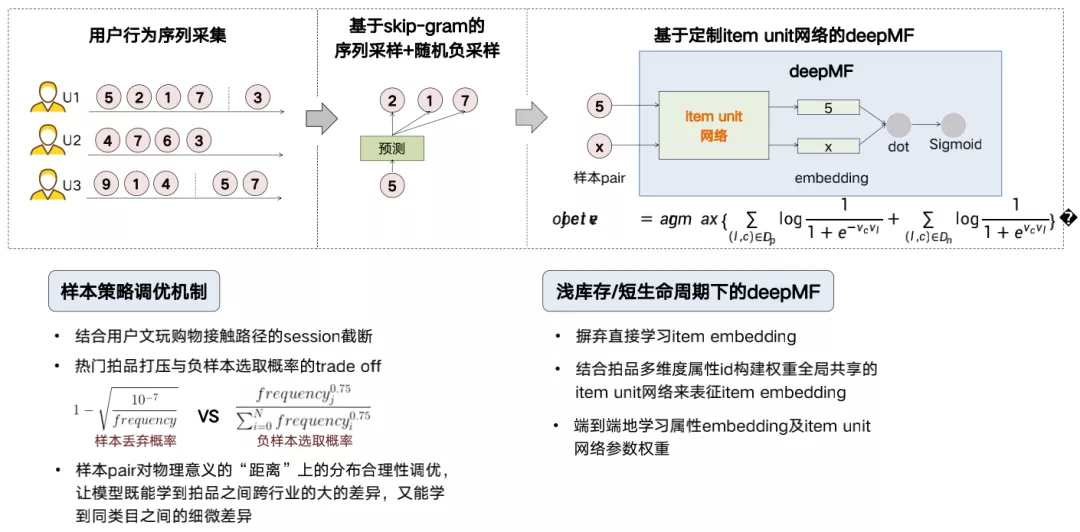
在外层结构上,我们应用了skip-gram的方式,通过用户行为序列构造的句子,在设定的window size里面抽取正样本,并进行负样本的随机采样。在这个基础上,我们结合文玩行业本身的业务特点进行样本的调优,比如:对文玩的购物决策行为序列进行session截断,对热卖店铺的打压以及拍品被选为负样本概率的整体调参,使得正负样本在业务上的差异性保持多样化。
在内层结构里,我们构建了DeepMF+item unit的网络,对每个拍品,我们构建权重共享的item unit子网络,子网络的输入是编码后的拍品的多维度属性id(无item ID),输出是代表拍品的embedding,通过item unit子网络输出的embedding pair经过DeepMF构造内积,经过Sigmoid去拟合0或者1。通过这个网络,我们解决了浅库存,短生命周期的拍品没有办法直接去训练item embedding的问题(即,用拍品的多维度属性id构建item unit网络端到端地学习embedding)。
2. Item unit的网络结构
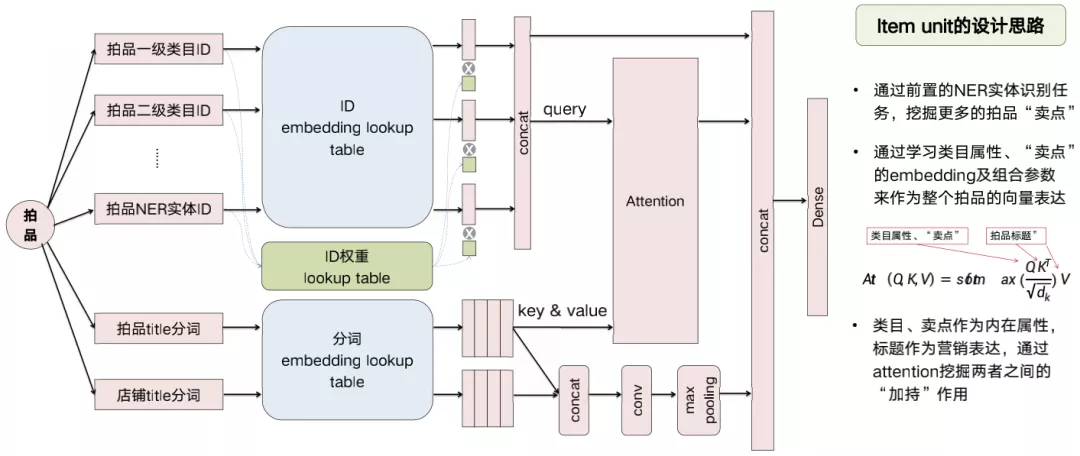
上图是item unit的网络结构细节:网络的输入是代表拍品所有相关属性的id,输出是拍品本身的embedding。对于任何一个新上架的拍品来说,只要这些属性是确定的,我们就能利用历史信息去计算这个拍品的embedding。这些确定性的属性是来自于多方面的信息,包括拍品所属的类目、NER识别的属性实体、图像算法挖掘的tag等。
在id类的信息表达上,我们既有id的embedding lookup table,又有id的权重table,这两者的相乘才是属性代表的embedding,再参与到整体的模型学习中。
为什么要用embedding乘以它的权重?其实是出于对零售业的商业逻辑的思考,一个典型的例子:同样一件运动裤,同样的材质,类似的款式,耐克能比李宁卖的更贵,其原因大部分来自于品牌的溢价,还有一小部分可能是来自于品牌下的独特的款式设计。所以在表达商品embedding时,品牌、属性、款式这些特征id在embedding中占有的权重天然应该是不一样的,我们期望模型能够学习到不一样的权重。
另外,在这个模型里,我们还将拍品的类目、实体属性id,与拍品的标题做了Attention:用属性id作为query,title作为key和value。这也是我们基于电商的业务理解后的一个尝试,因为类目属性,往往代表拍品的内在特质和卖点,而标题则是拍品的外在营销表达,商家会在标题里面带上略显夸张的营销词/广告词,而不同的词能够对不同卖点的拍品营销效果起到不同程度的加持作用,所以我们希望模型能够学到这种加持作用(类似于帖子或者视频的标题党能够带来额外的点击),这些融合业务知识的探索都是为了让模型更好地学习拍品在不同特征上的细微差别产生的整体的embedding变化。这也是我们基于拍品embedding的最核心的网络结构。
04 跨域学习搜索关键词意图embedding
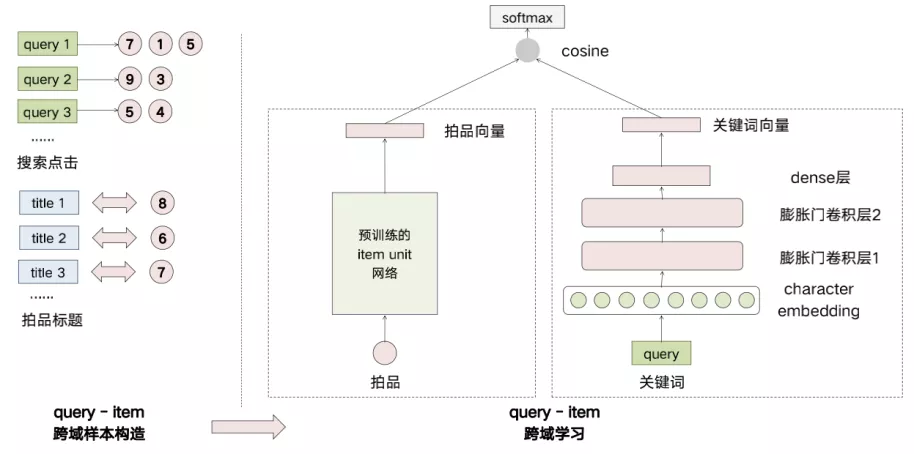
得到拍品的embedding之后,我们还希望把用户的搜索词和兴趣都映射到同一个向量空间来分别表达搜索意图和用户的多兴趣点。我们采用了跨域的思想来学习搜索词embedding,首先构建搜索词和拍品之间的跨域样本(正样本是来自于搜索之后的拍品点击,以及拍品和标题之间的关系,负样本随机抽样之后调优)。然后通过搭建两个域的DSSM双塔模型,在拍品域,我们用预训练的item unit网络来代表拍品的embedding(左边的部分),在右边的搜索词域我们通过字的embedding再加上两层的膨胀卷积门、一层的MLP来表达词的embedding,然后再通过DSSM这种训练的方式来学习样本之间的正负对关系。通过这种方式,把拍品的embedding迁移到了关键词上,使得两者处在同一个向量空间。最终两个域都会端到端地更新参数,从而得到了代表搜索意图的关键词embedding。
05 用户多兴趣embedding学习
1. 业务问题

在用户多兴趣的学习模型里,主要解决三个业务问题:第一,如何学习用户在一个session中表现出来的多峰兴趣,比如,在逛淘宝时,消费者可能同时在找他喜欢的衣服和手机。第二,如何更好地融合用户的短期行为和长期行为中的兴趣表达:我最近30天看的和最近5分钟内看的,如何影响我接下来的购物决策。第三,如何学习用户的多个兴趣并保持多个兴趣embedding之间的差异性和独立性。
2. Fusion Gate & Selection Gate
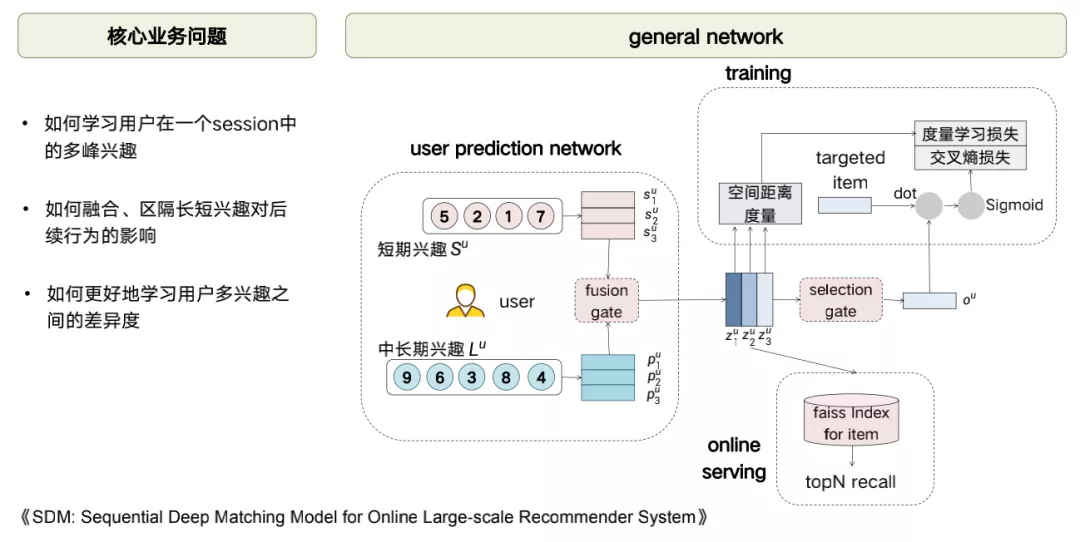
上图是用户多兴趣模型的整体网络结构,左边部分借鉴了阿里的SDM,同时我们在这个基础之上做了三个改进:第一,我们通过fusion gate融合门学习的向量从一个变成了三个,来代表用户的三个不同的兴趣;第二,为了让三个向量往不同的方向收敛,我们又设置了另外一个门:selection gate(0/1门),保证每一次只有一个向量去跟target item做交互;第三,为了增加三个向量之间的区隔度,我们还加入了度量学习的方法来保证三个向量之间的两两差异度。
最终的损失函数会包括交叉熵的损失函数和度量学习的损失函数,两个函数来共同优化来达到最优。最终模型的结果,我们会将selection gate之前的这三个向量作为用户的三个兴趣的表达。
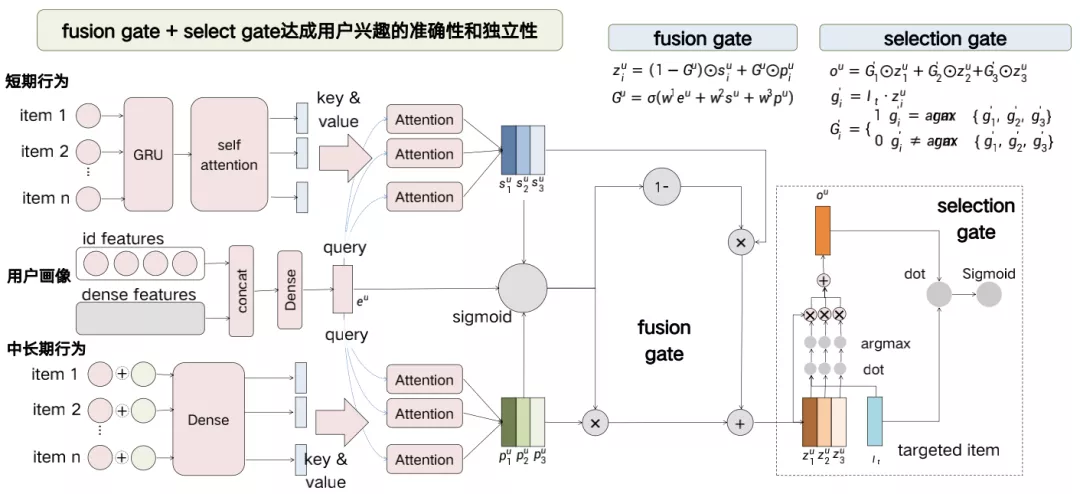
这个是我们多兴趣向量模型的细节,左边部分跟SDM基本上一致,只是我们在短期/长期行为以及用户标签的选择上,我们会结合文玩行业的特点做一些调整,包括我们把短期行为的LSTM换成了GRU,然后通过短期行为、长期行为各自和用户画像标签去做Attention,分别学习三个兴趣的embedding。并且三个短期和中长期的兴趣通过我们共享参数的fusion gate融合成三个不同兴趣的embedding。
Fusion gate起到了融合短期和长期行为权重的作用,而在selection gate这部分,三个向量会各自跟target item做embedding的内积,而selection gate是一个0/1门,所以每次只会选择内积最大的向量作为output embedding。然后output embedding会再次与target item做内积之后,再过Sigmoid拟合点击或不点击的label。所以这两个门起到了不同的作用,fusion gate的作用是融合兴趣在时间跨度上的表达,而selection的作用是对不同兴趣点的选择与更新。
3. 度量学习
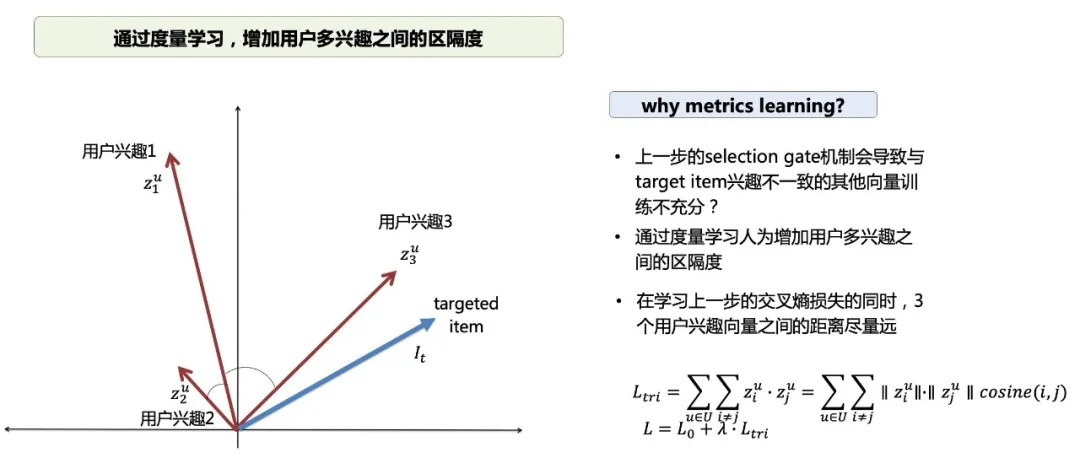
在实际的建模过程中,我们发现只用selection gate的输出结果作交叉熵损失函数,结果不够严谨,这也是为什么要加入度量学习的原因。因为我们为了让兴趣更加聚焦,每一次只更新一个兴趣向量,所以如果一个用户的兴趣本身比较集中(或者多兴趣点的行为频度也就是样本量差异很大),就会导致另外两个兴趣向量没有办法得到充分的训练。最终这三个兴趣向量表达的可能只有一个向量是有效的。
基于这一点,我们在训练内积最大的那个兴趣向量的同时,还要保证这三个兴趣向量之间的距离要充分的大,所以最终的损失函数会在上一步的交叉熵损失函数基础上加上度量学习的损失函数(两两兴趣向量的内积最小化)。
为什么选择内积?我们通过实践后发现:通过内积的方式,能挖掘出更多的信息。因为假设当用户只有一个兴趣向量的时候,另外两个向量会更多地参与到度量学习的损失函数里,而很少参与到targeted item的交互,这两个向量为了使损失函数变小,它就会朝着两两之间内积变小的方向去变化,这也加速了向量模变小的趋势。
当我们发现训练出来的某一个向量模很小时,就知道了这个向量过多的参与了度量学习的损失函数,也就是说这个向量作为兴趣向量的置信度,相对是比较低的。所以我们通过这种方式不仅学习到了兴趣向量还学习到了兴趣向量的置信度的衡量方法。

上图反映了是否使用度量学习的差异。我们抽样了某个用户,把他的三个兴趣向量映射到了距离最近的类目,发现如果不使用度量学习,每一个兴趣向量里面都和茶叶比较相似(因为他最近浏览了很多茶叶),这3个向量代表的兴趣点不够独立和多样性。对比加入度量学习的方法,发现训练出来的三个向量在类目上的差异更大。而且发现,相关度较低的向量的模长会更小一点,模长可以作为未来我们要不要使用这个兴趣的置信度。所以通过度量学习我们提升了多兴趣之间的区隔度,也提升了单个兴趣的聚焦程度。
4. 多兴趣向量的进一步发散

构建用户的多兴趣模型后,我们可以用它来召回拍品索引中的top N最近邻了。但是我们还希望对这个问题做进一步的发散:能不能用用户的多兴趣向量来增加推荐内容的多样性。因为在文玩行业当中大部分用户的兴趣聚焦在一到两个类目,给推荐多样性带来了比较大的困难。所以我们期望不仅能够召回到符合用户兴趣的拍品,还能够召回到其他潜在的感兴趣的拍品来扩大用户的兴趣半径。我们期望通过用户的多兴趣向量来提升用户惊喜感:在用户从来没有看过的类目里去召回跟他兴趣embedding比较像的拍品。
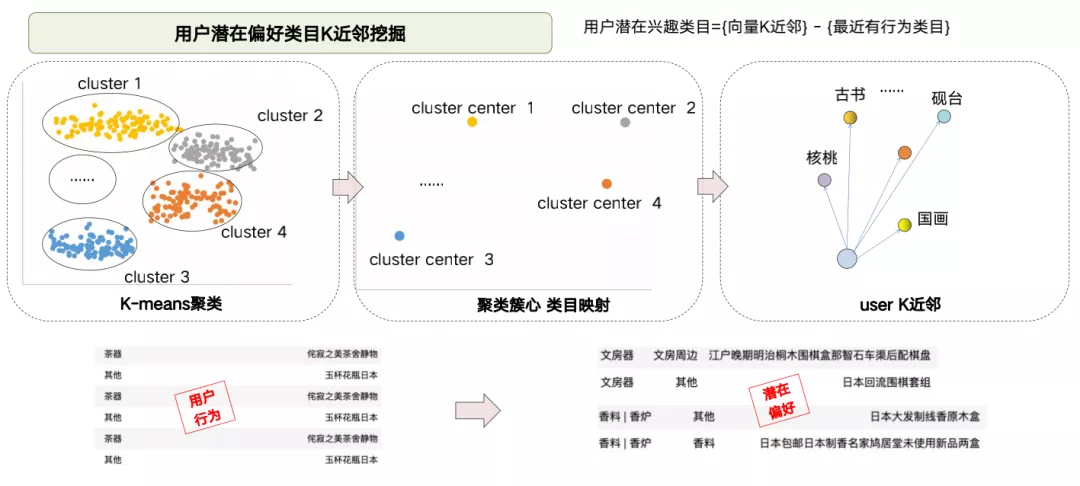
5. 用户潜在偏好类目K近邻挖掘
在上一步的工作后,用户和拍品已经在同一个向量空间了,我们对每个类目下的拍品分别进行聚类,找到N个簇心。对于每个类目都计算出簇心之后,我们可以利用用户的向量去计算跟簇心之间的K近邻,而K个簇心所代表的N个类目就表示跟用户需求兴趣最接近的N个类目,排除了用户有行为的类目之后,剩下的类目我们把它表达为用户的潜在偏好类目,比如,我们通过下面这个例子从用户过去的茶器行为发现他比较偏好日本元素,多兴趣向量可以在他从没有看过的文房器和香炉等类目里召回他所感兴趣的日本元素相关的拍品。
6. 如何在faiss中带类目约束地召回最近邻

接下来我们要做的是怎么从N个类目里各自召回跟用户向量最接近的M个最相似的拍品。因为所有拍品都在一个faiss索引里面,怎么带约束地召回最近邻?显然用先召回再做类目筛选过滤方法不可行,因为召回之后再过滤并不一定能得到所需要的类目。
所以我们先对拍品和用户的向量标准化,变成了模长为1的单位向量,这样向量之间的余弦距离就等价于欧氏距离,然后我们对所需要召回的那个类目,在某个维度的元素值上加上一个远大于1的值,不同类目的拍品在不同的维度上加。如上图示意:左边的部分国画和核桃原本是非常接近的,对核桃在y上加上一个比较大的值,对国画在x上加上一个比较大的值,就把国画和核桃在空间上平移开了,并且能够保证核桃内部的两两之间的距离最大值会远远小于核桃和国画之间的距离最小值,对于用户兴趣向量,如果要召回确定的类目,就在跟这个类目相同的维度上加上相同的值,这样基于欧氏距离召回的K近邻就一定属于这个类目。
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%BE%AE%E6%8B%8D%E5%A0%82%E6%B7%B1%E5%BA%A6%E5%8F%AC%E5%9B%9E%E5%9C%A8%E6%96%87%E7%8E%A9%E4%B8%AA%E6%80%A7%E5%8C%96%E6%8E%A8%E8%8D%90%E4%B8%AD%E7%9A%84%E5%AE%9E%E8%B7%B5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


