快手技术副总裁郑文为什么说是短视频平台的核心能力
本文转载自快手AI技术副总裁郑文CSDI演讲
量子位 授权发布 | 公众号 QbitAI
7月初举办的中国软件研发管理行业峰会(CSDI)上,快手AI技术副总裁郑文针对AI技术在短视频领域的应用做了精彩演讲。他介绍了人工智能技术是如何在快手整个业务流程中发挥作用,以及互联网公司如何从0开始成功推进一个AI项目。
郑文是美国斯坦福计算机系博士,研究方向主要集中在计算机图形学和电影特效方面,毕业之后在美国从事机器学习和计算机视觉相关研究,2016年回国后加盟快手,现任快手AI技术副总裁。
以下是演讲内容,有删节:
大家好,我是来自快手的郑文,今天与大家分享一下快手在AI技术应用上的一些经验。
首先,介绍一下快手的使命:用科技提升每一个人独特的幸福感。这里有两个关键词,一个是“每一个人”,一个是“独特”。
“每一个人”是指我们不会只针对某一个群体的人或者某一个区域的人,而是希望提升所有人的幸福感。
“独特”是指我们尊重不同人群、不同背景的人,他们的价值观,他们的审美观,不会因为一群人的审美倾向去歧视或区别对待另一群人的审美。
目前,快手通过记录的方式来达到提升每一个幸福感的目标。在内容消费端,用户有看到更广阔世界的需求;在内容生产端,相信每个人都有表达自己的欲望。所以,我们提供一个平台,可以通过记录自己,分享自己的日常点滴,进而去消除每个人的孤独感,提升幸福感。
表面上看,短视频平台似乎与AI技术没有什么关系。但实际上,人工智能技术是连接内容生产端与内容消费端的核心能力。为什么这么说?今天就跟大家分享一下快手在这方面的实践。
一、AI技术贯穿于快手从内容生产到内容分发所有过程
目前,快手已经积累了超过50亿条短视频以及数亿用户,面对如此大的规模,将每个人的注意力有效分配到海量的丰富内容,而非聚集在少数爆款视频上,通过人工的方法是行不通的,必须通过人工智能技术。
快手在AI技术上投入非常大,人工智能技术对解决内容与用户匹配的问题非常关键,贯穿于从内容生产到内容分发的所有过程。
1、内容生产环节:AI技术让记录形式更有趣

内容生产环节,通过AI技术可以把记录这个形式变得更加有趣。例如,我们上线了一些爆款特效,如“变老”表情、肢体识别舞蹈游戏、AR换脸特效,这些玩法背后是快手对最先进AI技术的开发,包括人脸关键点、人体姿态估计、手势识别、背景分割等。
AI技术在这一环节的应用难点在于,快手用户覆盖面非常广。据不完全统计,快手用户手机型号超过5万种,包含很多中低端机型,怎么让最先进的AI算法在这些机型里面运行起来是非常有挑战性的。
为此,我们自主开发了一个深度学习引擎,针对每种机型的硬件配置进行专门优化,进而可以在这个基础之上开发各种AI技术,目前我们有做过横向比较,快手自研的引擎与其他开源引擎相比,有非常高的提升。
2、视频内容理解:让AI看懂视频
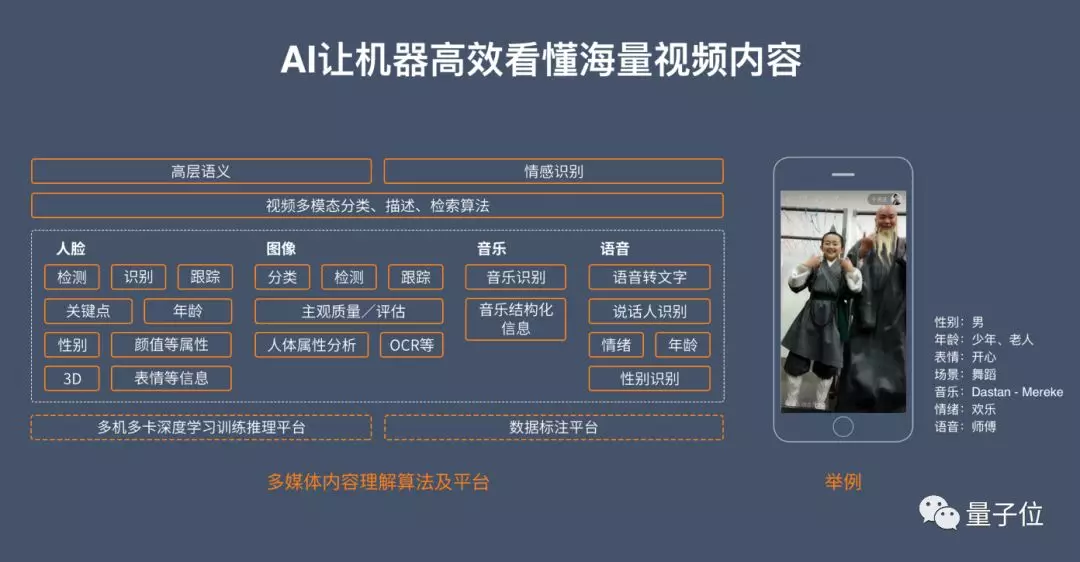
在视频内容生成、用户将视频上传到快手后端以后,我们会让机器根据视频的内容进行一些理解,提取视频中的一些基本信息,比如识别视频中人脸的年龄、性别,甚至表情、颜值等等。
机器也会进行图像分类,例如场景识别、物体跟踪、图像质量评估、OCR文字识别等。通过音乐识别,我们能够实现音乐的版权保护。在快手,语音识别也是非常重要的一部分,通过机器将语音转化为文字,然后从文字当中得到这个视频想表达的含义。
通过人脸、图像、音乐、语音这些信息,机器能够提取最高层的语义,从而识别视频的感情。
3、用户理解:让机器深度洞悉用户

对快手用户,机器也同样需要做一些理解。首先我们可以根据用户注册的信息,以及他使用当中的一些情况得到一个基本信息,比如年龄、性别、地域、是否使用Wifi等,同时用户在使用快手过程中也会产生大量的行为数据。这些信息都会被送入到一个深度学习的模型当中去训练,从而得到一个用户向量,来描述这个用户,并从向量当中预测这个用户到底喜欢什么东西,以及他和其他用户之间的关系。
4、视频与用户的双向匹配
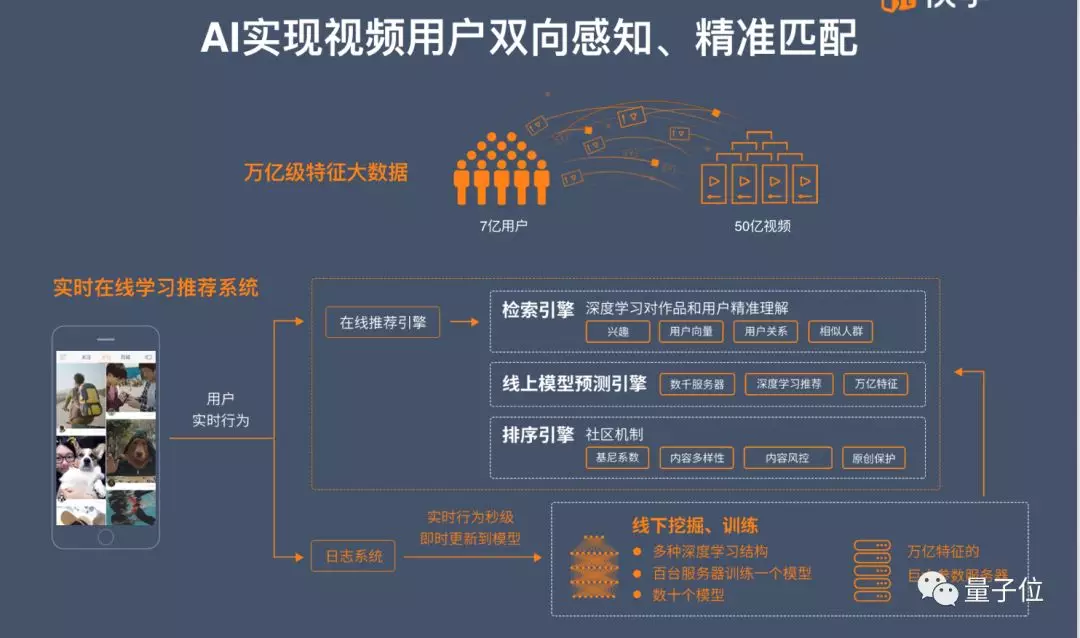
50亿的视频与数亿用户向量匹配在一起,就能够产生一个万亿级的大数据。用户使用APP的过程中,用户使用数据会输送到日志系统,以秒为单位实时更新线下的模型,这些模型再发送到排序引擎进行更新,保证内容分配的多样性,控制视频之间的流量分配差距。
用户的行为数据也会输送到我们的推荐引擎里,去索引用户现在有可能想看的东西。此外我们还有一个线上的预测模型,预测他现在的兴趣是什么,再根据机器对用户的理解,以及对跟用户有关系的人的理解,去推荐视频。
二、AI项目如何从0到1
人工智能相对来说是一个比较新的技术,现在可能还没有一个非常成形的流程,但是根据我的经验,大概把整个过程分成几个阶段。为了表述清楚,我画了一个流程图,实际执行的过程有可能会在每个阶段之间进行反复。
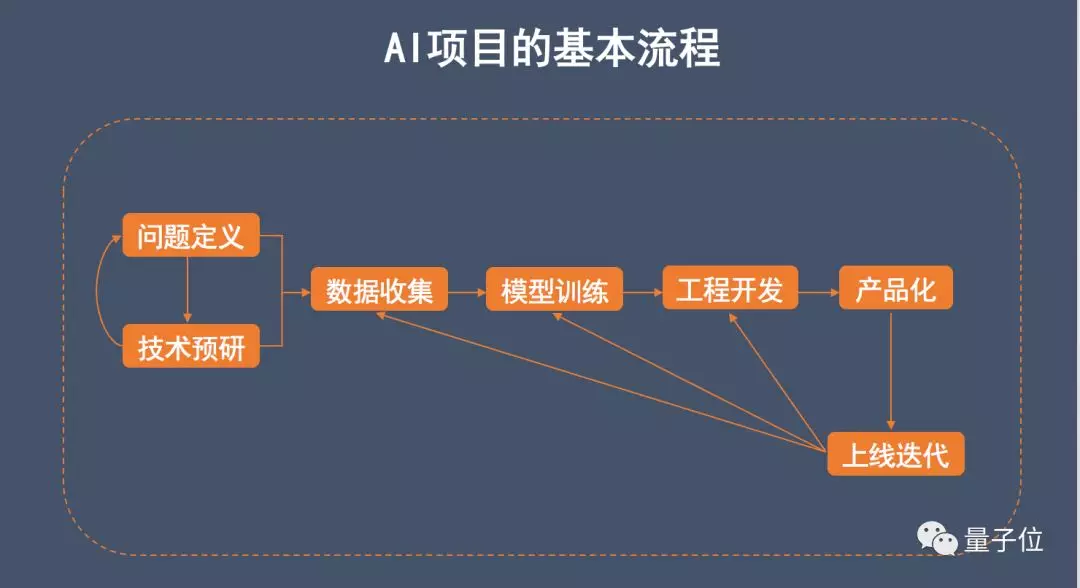
首先,我们要弄清楚解决的是什么问题,然后针对这个问题去进行技术的预研究,预研的过程有可能需要反复修改问题。这两步都确定下来之后要开始收集数据、训练模型,去做相应的功能开发,最后进行产品化,产品化之后还要上线迭代,迭代过程中可能会产生问题,需要重新去构建模型开发。
1、问题定义:从产品出发,数据A到数据B
现在大家讲到AI可能更多谈到的是深度学习技术里面的监督式学习技术,这类技术解决的问题就是把数据A映射到数据B。比如人脸识别技术中,数据A是人脸图片,数据B就是这个人的ID。这个问题就是要解决,通过人脸图片怎么知道这个人是谁。
现在所有的AI项目大概都可以归纳成这样一个问题。所以,首先要搞清楚数据A和数据B分别是什么。同时要从产品本身的需求出发,明确产品需要做到什么样的程度,比如门禁系统的人脸识别和手机上的人脸识别,数据、限定条件等都是有差别的,两个产品对技术的要求也是不一样的。
2、技术预研:数据复杂度、关系复杂度与数据量
解决问题定义之后,我们就会去做一些技术调研,确定现代技术的边界在哪里,包括什么技术是能做的,能做到什么程度,以及做到这个程度需要多少代价。
技术的确定,首先要考虑数据本身的复杂度。比如我们刚才说的人脸,数据的复杂度相对较低,因为人脸五官比较固定。而在人体识别中,四肢之间的关系是会变化的,相对来说复杂性就要提升一个量级。
另外就是关系的复杂度。如果做人脸识别,数据A到数据B的映射关系是非常直接的。但是如果你要去识别一个视频里有没有暴力内容,这个关系就会非常复杂,它不仅仅是机器看到的图象后联想到什么概念,可能还需要很多辅助信息,包括很多人才能够理解的常识性的东西,会有很多壁垒。
3、数据收集:数据质量很重要
确定了问题以及技术方案后,就可以收集数据了。一般来说AI项目的大部分时间都是在做数据,甚至有的时候问题还没产生就开始有意识地收集数据,因为说不定将来有些问题的解决会有用。数据质量越好,你做出来的东西质量也越好。
首先,数据量需要充足。通常,越复杂的问题,或者说问题的多样性越大,所需要的数据量越大,数据量决定了你需要花多大的代价做这个事情。
接下来,要对收集到的数据做标记,如果数据上有大量的标记错误,这个数据基本上就没法用,所以需要进行数据清洗,一遍遍地进行数据纠错,提升数据质量。
数据分布也很重要,必须满足产品要求的所有应用场景。比如,人脸识别如果需要识别侧脸,那么数据当中就需要有足够的侧脸数据,否则分布就不够好。
4、模型训练:准确评价模型
数据准备好以后,就进入训练模型的环节。这里的关键是你怎么去评价这个模型。
首先,测试集的设计非常重要,测试模型用的数据和用来训练模型的数据必须是完全分开的,测试时一定要用模型没看过的数据去检验这个算法做得好不好。
测试数据的选择也是非常重要的,不同的测试数据有可能导致你检验的结果完全相反,所以这个设计必须以产品要求的应用作为出发点,就是需要涵盖哪些不同的CASE,针对每个CASE都要有一些不同的测量数据,最后才能得出结论,这个技术是不是能够满足产品需求。
另外模型设计也需要考虑性能要求,比如是在手机上线,还是在一个后端服务器上线,两者对计算资源的消耗要求不一样。手机上可消耗的资源会受到限制,那么模型就要做得非常小。
5、工程开发:基础架构保证高性能,辅助算法完成最后10%
模型训练后、产品上线前,还需要有一定辅助的工程。比如在后端上线,要有一个基础的深度学习特定集群,一般都是CPU集群。如果是在手机端上线,需要在手机上有一个引擎,像快手自己开发的YCNN引擎就是属于这种基础架构,对模型和技术的性能有着很大影响。
另一方面,除了AI升级的算法本身,一些传统算法的辅助也非常必要。例如AlphaGo,大家通常知道这是深度学习的成果,其实也结合了例如蒙特卡洛树搜索之类的传统算法才能达到它当时的成绩。很多时候解决问题,除了深度学习提供的模式识别能力,还要依赖推理、搜索等其他能力的辅助。
6、产品化:好的产品能化腐朽为神奇
工程开发结束就可以产品化了,一个好的产品设计是可以化腐朽为神奇的。很多技术有时并没达到一个非常好的状态,但可以用一些好的设计去规避技术缺点,发挥技术的长处。这个流程可能是在最后阶段,但是实际用户体验设计在问题定义的时候就已经开始了。
像一些用户反响很好的短视频特效,常常所用的技术仍有很多的局限性,但通过优秀的产品设计,却能扬长避短,把最终的用户体验做得很好,给用户带来惊喜。
7、版本迭代:持续改进
产品上线后,还需要对版本进行迭代,修复上线过程中发现的一些问题。这里需要强调的一点还是数据,数据占据了AI项目大概四分之三以上的时间。上线以后第一时间就要开始收集数据,因为这才是用户在使用时候的数据,是最贴合应用场景的数据,所以也是最重要的数据。
最后介绍一些我们在人工智能技术方向的未来规划。今年4月份,我们和清华大学共同成立了未来媒体数据联合研�
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E5%BF%AB%E6%89%8B%E6%8A%80%E6%9C%AF%E5%89%AF%E6%80%BB%E8%A3%81%E9%83%91%E6%96%87%E4%B8%BA%E4%BB%80%E4%B9%88%E8%AF%B4%E6%98%AF%E7%9F%AD%E8%A7%86%E9%A2%91%E5%B9%B3%E5%8F%B0%E7%9A%84%E6%A0%B8%E5%BF%83%E8%83%BD%E5%8A%9B/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


