推荐技术随谈
文章作者:翦浩 脉脉
编辑整理:蒋权
内容来源:DataFun AI Talk
大家好,今天想和大家讨论下相关推荐技术通用的特点及在实践中的改进点,这也是我们团队在研发实践中一些经验总结。
首先,推荐解决主要问题是给用户在没有行为的新闻上预测一个偏好概率,然后通过概率值由高到低排序推荐给用户。如图简单地表达了用户在新闻上的稀疏行为矩阵,通过我们会基于用户的画像特征、内容特征、上下文场景特征、用户对新闻的各种操作行为特征等对内容候选集进行排序打分。其中很直观的解决办法是通过计算用户之间相似或者商品之间的相似来推荐。
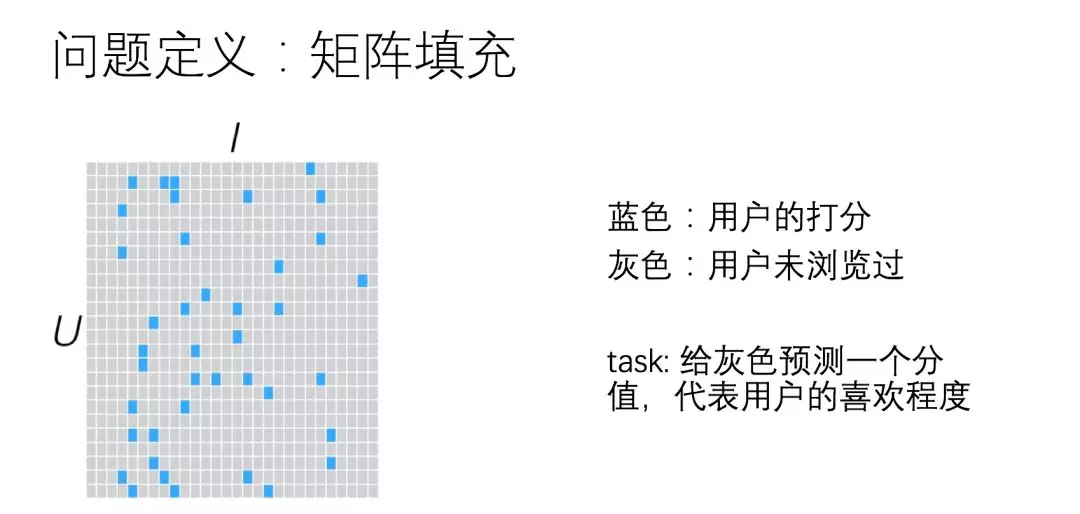
那么,协同过滤中 UserCF 模型和 itemCF 模型是最简单的办法。这里着重对两者进行对比:
1. itemCF 比较适合个性化推荐场景(比如,商品、电影、短视频等各种场景),它偏重当前用户的当前行为,从而能推荐与当前相关新闻的内容,而 UserCF 更偏群体性(比如,新闻推荐场景),计算当前用户的 K 个相似用户时,当 K 值偏大,UserCF 推荐更偏热点;
2. itemCF 兴趣扩展比 UserCF 弱,因为 itemCF 会根据你当前的行为推荐与当前相关的内容,不像 UserCF 能够学习到多个用户不同的偏好;
3. itemCF 能解决用户的冷启动问题,只要新用户对一个新闻产生行为,就能够推荐和该新闻相关的内容,相反 UserCF 能解决 item 冷启动问题,因为用户相似度计算通常是离线计算的,新闻上线后一段时间,一旦有用户对新闻产生行为,就可以将新上线的新闻推荐给和对它产生行为的用户兴趣相似的其他用户。

这里,用数学的角度去解释协同过滤为什么能够在推荐中可行。如下基本假设换成数学解释就是,一个矩阵向量,如果行向量部分相同,那么行向量其余部分也有可能相同,代数上解释就是向量线性相关性,那么线性相关带来的是向量低秩,即向量是冗余的,冗余的向量带来的信息和消耗的计算资源是完全可以避免的,那么如何进行矩阵压缩并且保证不影响信息的丢失是推荐技术中的另一个关键。

比如说,矩阵分解。如下一个比较大的稀疏矩阵(低秩)能够拆分成两个比较小的矩阵相乘。公式 _E _是由经验损失函数和结构风险函数组成的损失函数。
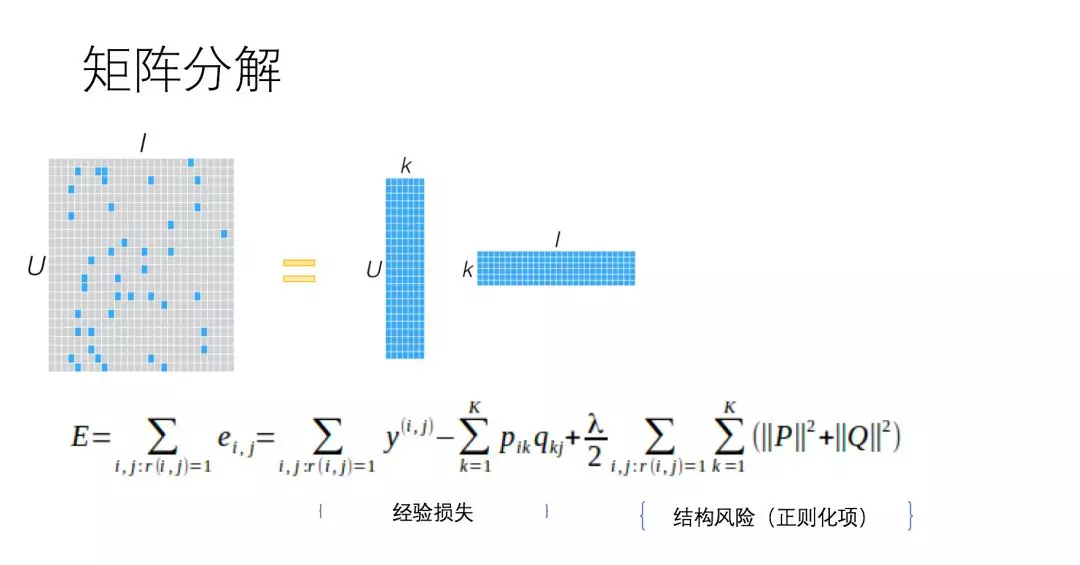
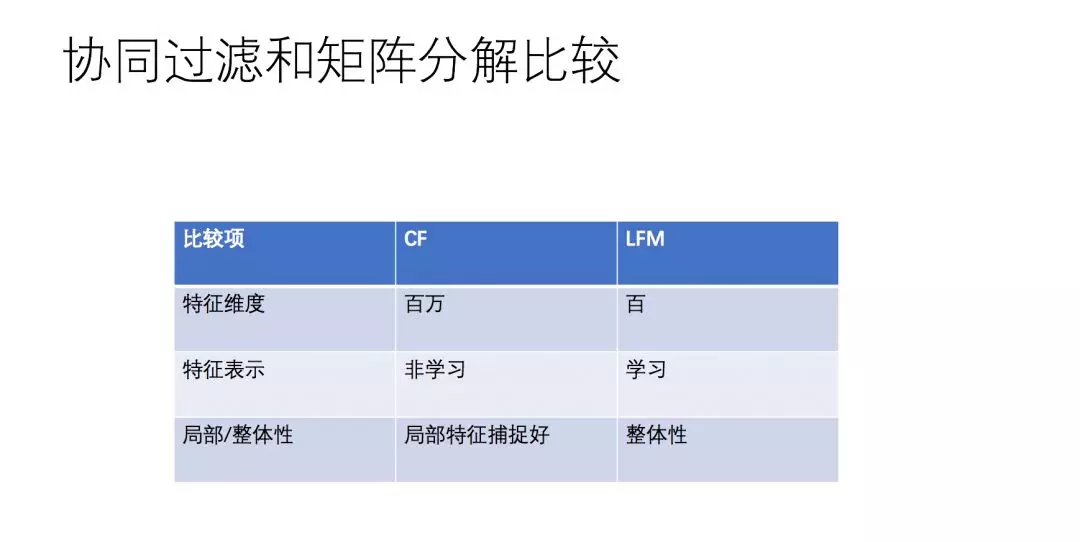
其实,基于前面的假设,协同过滤和矩阵分解两者具有很紧密的内在联系,只是两种不同的表达形式。我们需要弄清楚一个问题:超大维度矩阵表式形式带来的是信息的不相似,及稀疏数据计算的相似结果很有可能是不置信并且过拟合的,这样会导致信息准确性不足问题。在特征表示方面CF是维持了原有的元数据形式,能够捕捉更细粒度的局部特征,但这样带来的计算开销也是巨大的,所以,实际工业上出现了很多的变体方法。
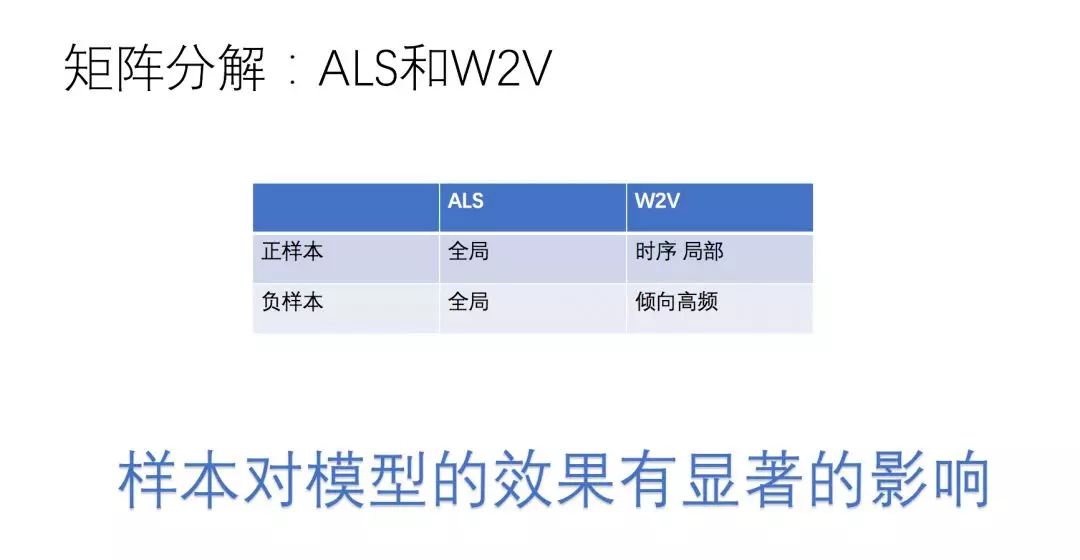
业界解决 item2vec 的常用的算法是 Spark 中的 ALS 和 Python 中的 Word2Vec。其中 Word2Vec 在序列表征用户和商品向量,然后直接计算相似度是非常熟知的方案。在实际的新闻信息流推荐中,Word2Vec 的点击效果比 ALS 要好30%+,主要有两个原因:
1. 用户的兴趣和行为是多样的,局部的行为往往更偏相关,往往整体的样本差异是很大的;
2. 在负样本采样中,ALS 是全局的负样本采样,Word2Vec 更倾向高频,倾向高频的采样更不容易让学习出的结果都与高频(头部)的结果相似。
我们思考一个问题,既然样本对模型的效果有显著的影响,那么我们想办法优化负样本会不会带来更大的提升呢?
针对 ctr 预测问题,我们把上一次点击、下一次展现和样本是否点击组成若干个三元组,然后我们去估计给定两个 item_id 的点击率,从而计算出两个 item 的相似。实践证明这种直接优化点击率目标函数的效果是非常好的,但是这种模型在遇到新的文章或者物品时是没法计算历史信息的,这其实是一个泛化性问题,怎么理解呢?

我们思考,能不能用一些泛化性的特征来表达 item_id 呢?当然可以。下面 side information 代表多个特征,熟悉 word2vec 的同学知道右边结构就是一个 skip-gram 的结构,给定一个 item_id,求其指定的窗口区间的 item_id,那么如果把 d3 替换成 itemid, keyword, category, author 等泛化特征,再放入模型中,word2vec 实质上变成一个多分类模型。同理,我们也可以在用户侧融入 side information。
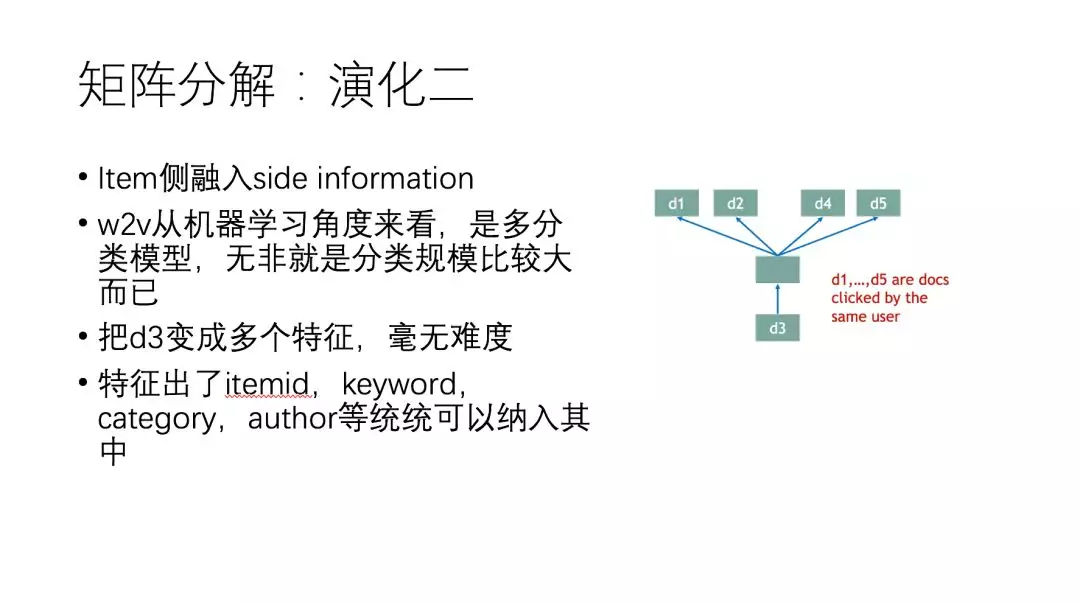
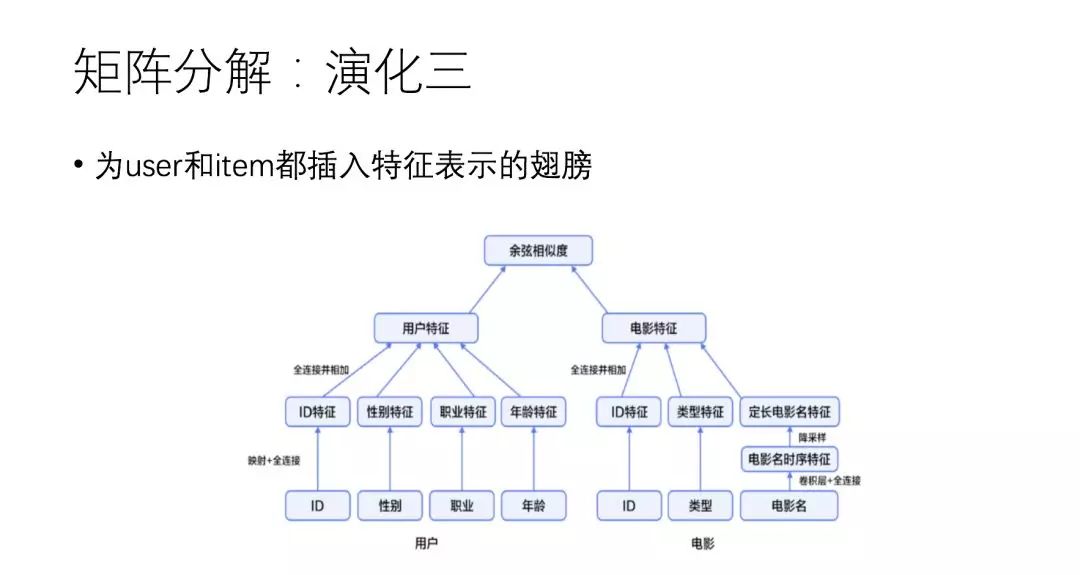
下面右侧图实际上是演化二的形式,只是在左侧用户特征部分也融入了 side information,然后用户特征和电影特征两两计算相似,其中一般通过神经网络学习特征之间的交互信息。从整体上看,抽象的来理解演化三上下部分分别对应的是矩阵分解和特征融合两个过程。
上面三种都是基于矩阵分解的演化过程,但是你会发现他们特征之间的分开融合的,也就是用户特征和商品特征分别融合后再计算相似。下面介绍一种特征之间交互更紧密的模型。
FM(Factorization Machines),主要是为了解决数据稀疏的情况下,特征怎样组合的问题。如下其前半部分是我们熟悉的逻辑回归,后半部分就是多个 MF(n 个向量与向量相乘)。无论 MF 还是 FM 最后都是得到特征向量的表式,特征之间先 dot-product 再加和,与特征向量先加和再 dot-product 性质是一样的,只是 FM 在进行特征交叉时二元特征交叉参数不是独立的,而是相互影响的。那么这里读者可以思考一个问题,FM 既然一开始是做 ctr 预估排序模型,那为什么也能做召回?

虽然“天下武功出一家”,但是每个模型都有它的不足之处,在实际项目中最后的推荐效果都是多个模型组合的效果。最有效也最容易的解决办法就是采用集成手段,从不同的角度生成多个 ctr 预估模型,然后通过 GBDT 去做适合 dense 特征交互,这样集成的方法效果是非常大的。

前面涉及到的都是追求的一个业务指标最大化的问题,其实往往在实际业务场景中追求的是多个指标。下面以电商为例,提升点击率不是最核心的,提升成交转化率才是目的,所以,如何在点击和转化两个目标平衡是非常关键的。我们的解决办法是分别建立 ctr 和 cvr 模型,排序公式:
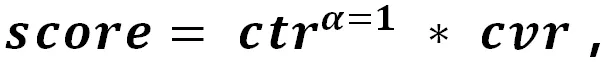
这里前提条件是两个模型预估准确率是非常高的。
另外,其中有个非常重要的超参是借助强化学习来解决的,超参可以理解你要求解的公式中相关的不确定的权重系数,这里不展开强化学习细节,业界强化学习在超参的调试中是比较成熟的解决方案。我们最后花了一周左右的时间调到最佳参数后成交率提升达到10几个百分点。
,商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


