推荐系统遇上深度学习十四
之前学习了强化学习的一些内容以及推荐系统的一些内容,二者能否联系起来呢!今天阅读了一篇论文,题目叫《DRN: A Deep Reinforcement Learning Framework for News Recommendation》。该论文便是深度强化学习和推荐系统的一个结合,也算是提供了一个利用强化学习来做推荐的完整的思路和方法吧。本文便是对文章中的内容的一个简单的介绍,希望对大家有所启发。
1、引言
新闻领域的个性化推荐十分重要,传统的方法如基于内容的方法、协同过滤、深度学习方法在建模user-item交互关系时,经常面临以下三个问题:
1)难以处理新闻推荐的动态变化。这种动态变化体现在两个方面,首先新闻具有很强的时效性,其次是用户对于新闻阅读的兴趣是不断变化的,如下图所示:
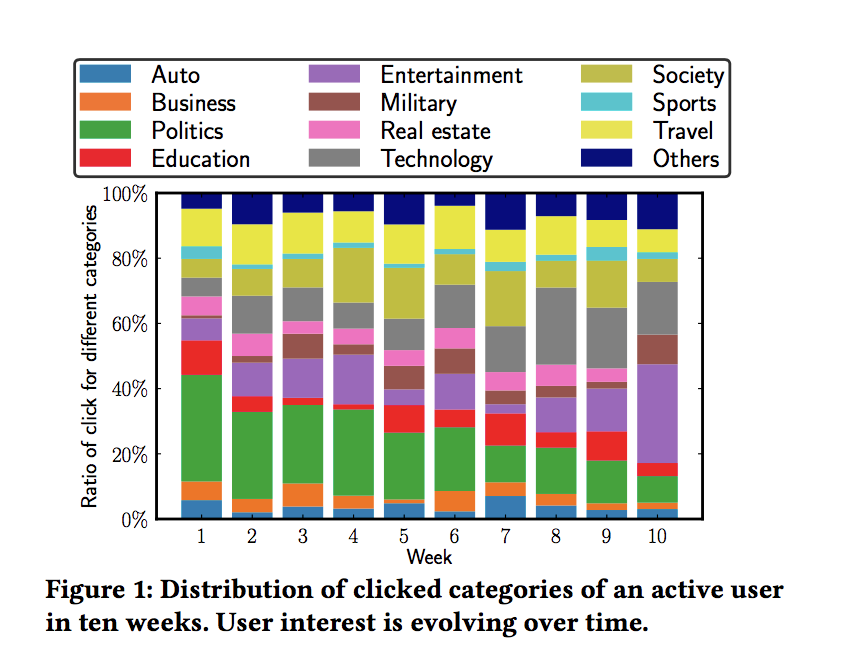
因此,在建模过程中,不仅要考虑用户对当前推荐的反馈,还要考虑长期的影响。就好比买股票,不能只考虑眼前的收益,而是要考虑未来的预期收益。
2)当前的推荐算法通常只考虑用户的点击/未点击 或者 用户的评分作为反馈,然而,用户隔多久会再次使用服务也能在一定程度上反映用户对推荐结果的满意度。
3)目前的推荐系统倾向于推荐用户重复或相似内容的东西,这也许会降低用户在同一个主题上的兴趣度。因此需要进行exploration。传统方法 e -greedy strategy 或者 Upper Con dence Bound (UCB) 都会在短期对推荐系统的效果造成一定的影响,需要更有效的exploration策略。
因此,本文提出了基于强化学习的推荐系统框架来解决上述提到的三个问题:
1)首先,使用DQN网络来有效建模新闻推荐的动态变化属性,DQN可以将短期回报和长期回报进行有效的模拟。
2)将用户活跃度(activeness score)作为一种新的反馈信息,用户活跃度在后面会详细介绍。
3)使用Dueling Bandit Gradient Descent方法来进行有效的探索。
算法的框架如下图所示:
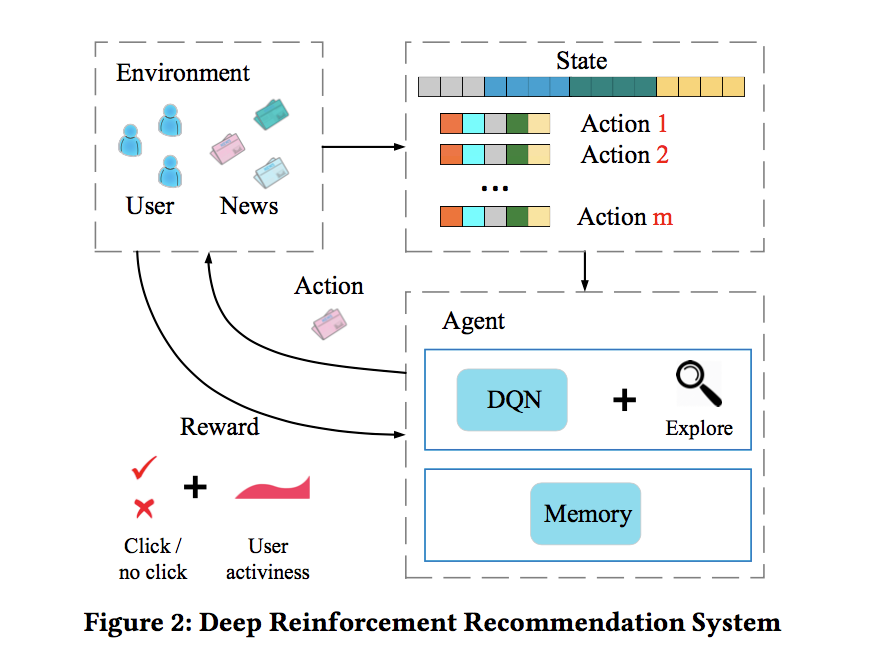
本文的贡献主要有:
1)提出了一种强化学习的框架用于在线新闻的个性化推荐
2)使用用户活跃度作为一种新的反馈,来提高推荐的准确性
3)使用了一种更加高效的探索算法:Dueling Bandit Gra- dient Descent
4)模型可以进行在线学习和更新,在离线和在线实验上的表现都超过了传统的算法。
2、问题定义
下面是本文中的一些符号约定:
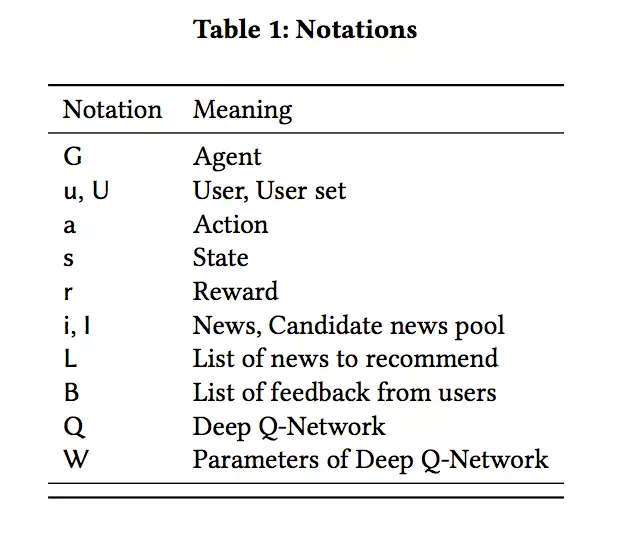
3、模型详解
3.1 模型整体框架
模型整体框架如下图所示:
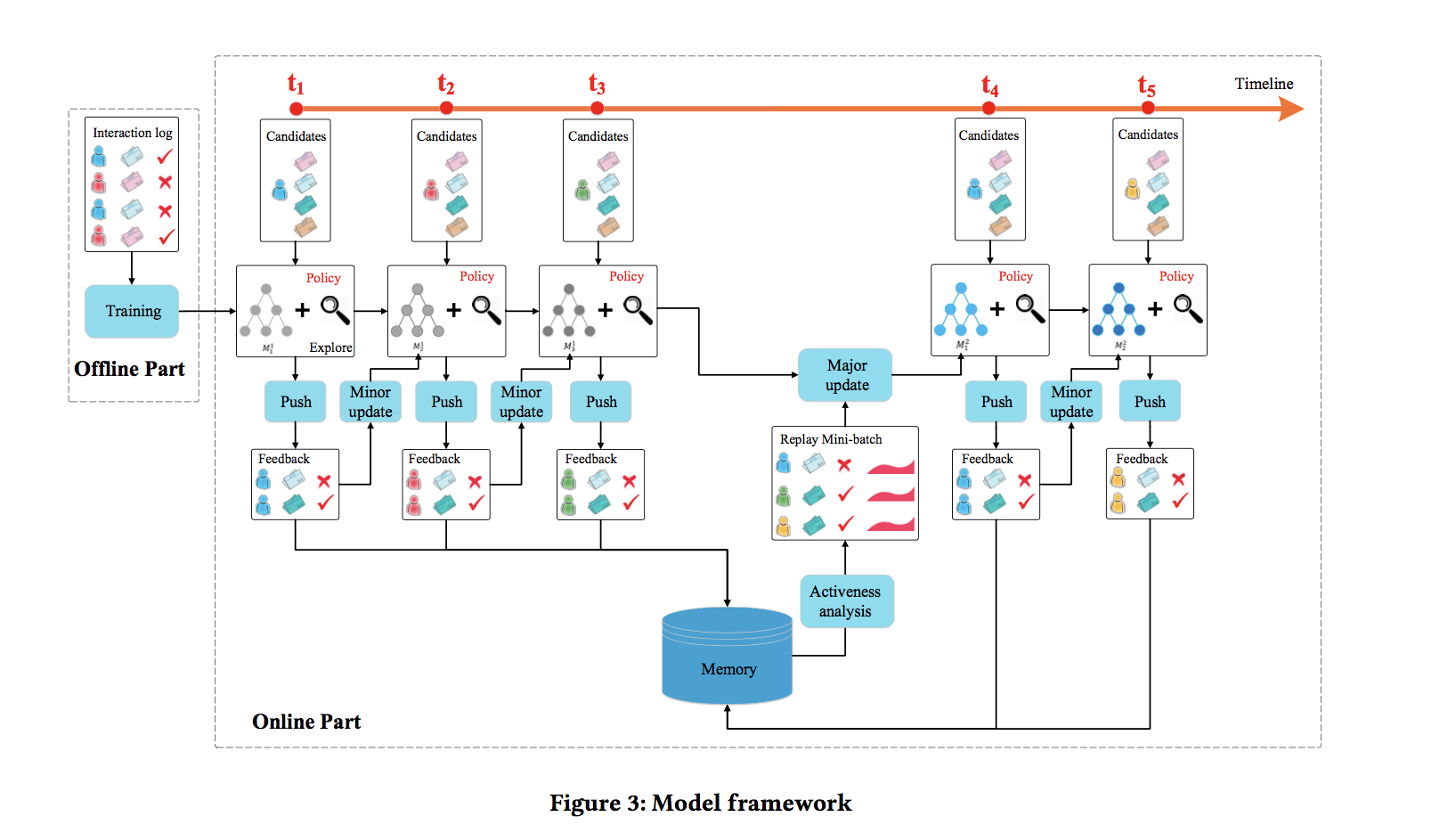
有几个关键的环节:
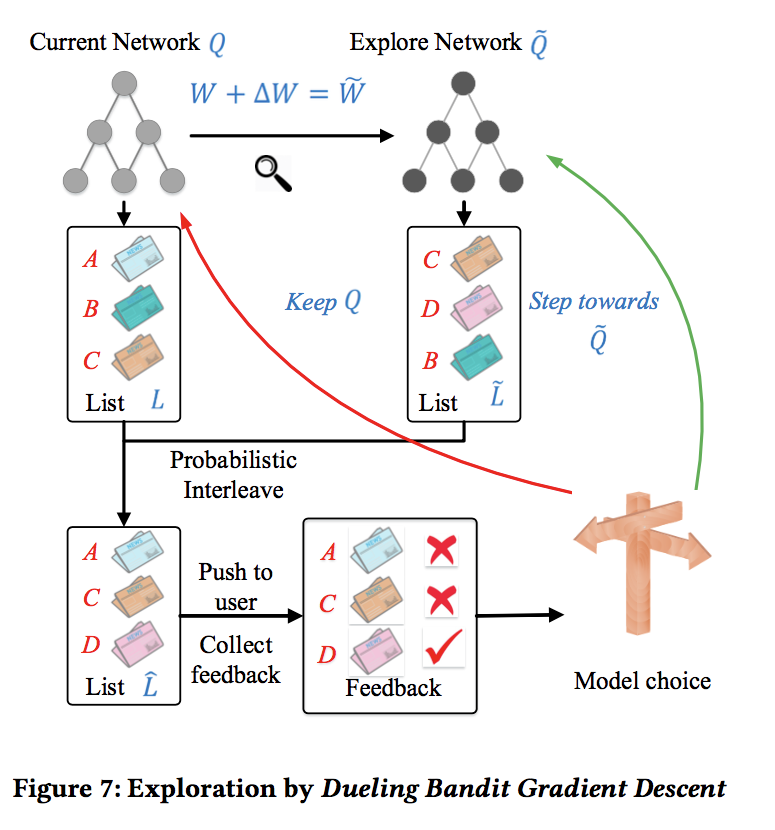
PUSH:在每一个时刻,用户发送请求时,agent根据当前的state产生k篇新闻推荐给用户,这个推荐结果是exploitation和exploration的结合
FEEDBACK:通过用户对推荐新闻的点击行为得到反馈结果。
MINOR UPDATE:在每个时间点过后,根据用户的信息(state)和推荐的新闻(action)及得到的反馈(reward),agent会评估exploitation network Q 和 exploration network Q ̃ 的表现,如果exploitation network Q效果更好,则模型保持不动,如果 exploration network Q ̃ 的表现更好,exploitation network Q的参数将会向exploration network Q ̃变化。
MAJOR UPDATE:在一段时间过后,根据DQN的经验池中存放的历史经验,对exploitation network Q 模型参数进行更新。
3.2 特征设计
DQN每次的输入有下面四部分的特征:
新闻的特征:包括题目,作者,排名,类别等等,共417维
用户的特征:包括用户在1小时,6小时,24小时,1周,1年内点击过的新闻的特征表示,共413*5=2065维。
新闻和用户的交互特征:25维。
上下文特征:32维的上下文信息,如时间,周几,新闻的新鲜程度等。
在这四组特征中,用户特征和上下文特征用于表示当前的state,新闻特征和交互特征用语表示当前的一个action。
3.3 深度强化学习作推荐
这里深度强化学习用的是Dueling-Double-DQN。之前我们介绍过DQN的三大改进,包括Double-DQN,Dueling-DQN和优先经验回放,这里用到了两个。将用户特征和上下文特征用于表示当前的state,新闻特征和交互特征用语表示当前的一个action,经过模型可以输出当前状态state采取这个action的预测Q值。
Q现实值包含两个部分:立即获得的奖励和未来获得奖励的折现:
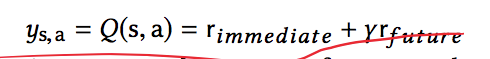
立即的奖励可能包含两部分,即用户的点击奖励和用户活跃度奖励。由于采取了Double-DQN 的结构,Q现实值的计算变为:
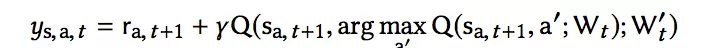
再加上Dueling的考虑,模型的网络结构如下:
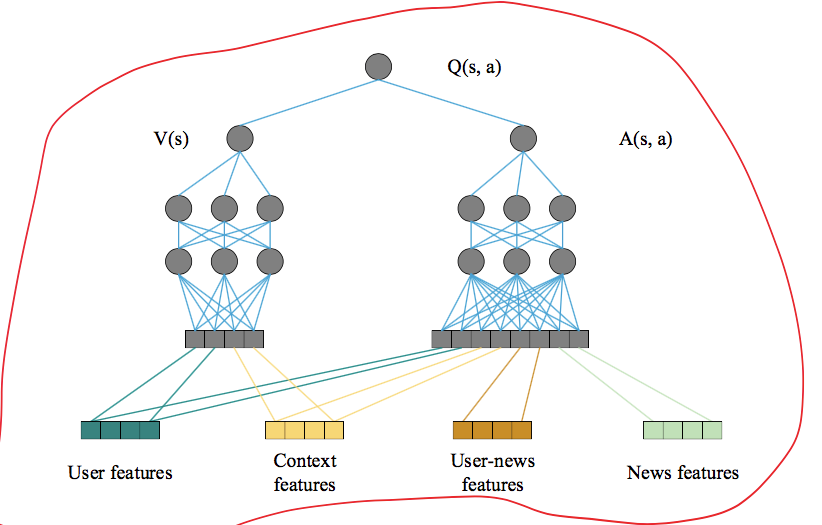
文章中关于DQN的理论部分没有详细介绍,可以参考我之前写过的强化学习系列的文章进行理解。
3.4 用户活跃度
用户活跃度(User Activeness) 是本文提出的新的可以用作推荐结果反馈的指标。用户活跃度可以理解为使用app的频率,好的推荐结果可以增加用户使用该app的频率,因此可以作为一个反馈指标。
用户活跃度的图示如下:
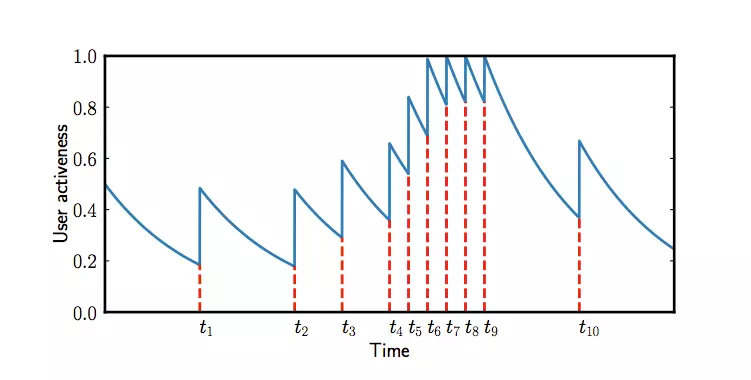
如果用户在一定时间内没有点击行为,活跃度会下降,但一旦有了点击行为,活跃度会上升。
在考虑了点击和活跃度之后,之前提到过的立即奖励变为:
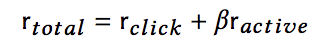
3.5探索
本文的探索采取的是Dueling Bandit Gradient Descent 算法,算法的结构如下:
在DQN网络的基础上又多出来一个exploration network Q ̃ ,这个网络的参数是由当前的Q网络参数基础上加入一定的噪声产生的,具体来说:
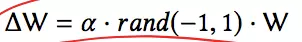
当一个用户请求到来时,由两个网络同时产生top-K的新闻列表,然后将二者产生的新闻进行一定程度的混合,然后得到用户的反馈。如果exploration network Q ̃的效果好的话,那么当前Q网络的参数向着exploration network Q ̃的参数方向进行更新,具体公式如下:
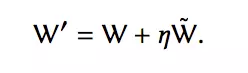
否则的话,当前Q网络的参数不变。
总的来说,使用深度强化学习来进行推荐,同时考虑了用户活跃度和对多样性推荐的探索,可以说是一个很完备的推荐框架了!
4、实验比较
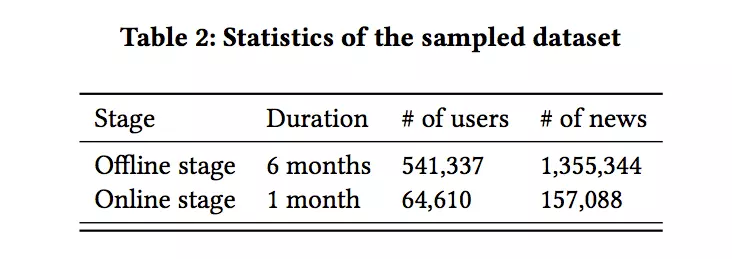
4.1 数据集
使用的数据集是新闻app得到的数据:
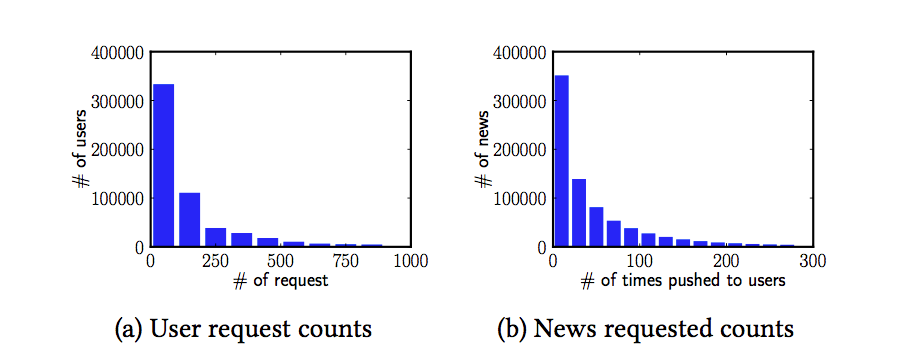
数据中存在明显的长尾特点:
4.2 评估指标:
主要用的评估指标有CTR、top-K准确率,nDCG,三者的计算公式如下:
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%8E%A8%E8%8D%90%E7%B3%BB%E7%BB%9F%E9%81%87%E4%B8%8A%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E5%8D%81%E5%9B%9B/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


