深入理解推荐系统超长用户行为序列建模
【推荐系统】专栏历史文章:
深入理解推荐系统:Fairness、Bias 和 Debias
作为【推荐系统】系列文章的第七篇,将以CIKM2020中的一篇论文“Search-based User Interest Modeling with Lifelong Sequential Behavior Data for Click-Through Rate Prediction”作为今天的主角,主要介绍针对Lifelong用户行为序列建模的方案,用户行为长度可以达到上万,而且可以像DIN那样,对于不同的候选商品从用户行为里查找有效的信息建模用户的特殊兴趣。
背景
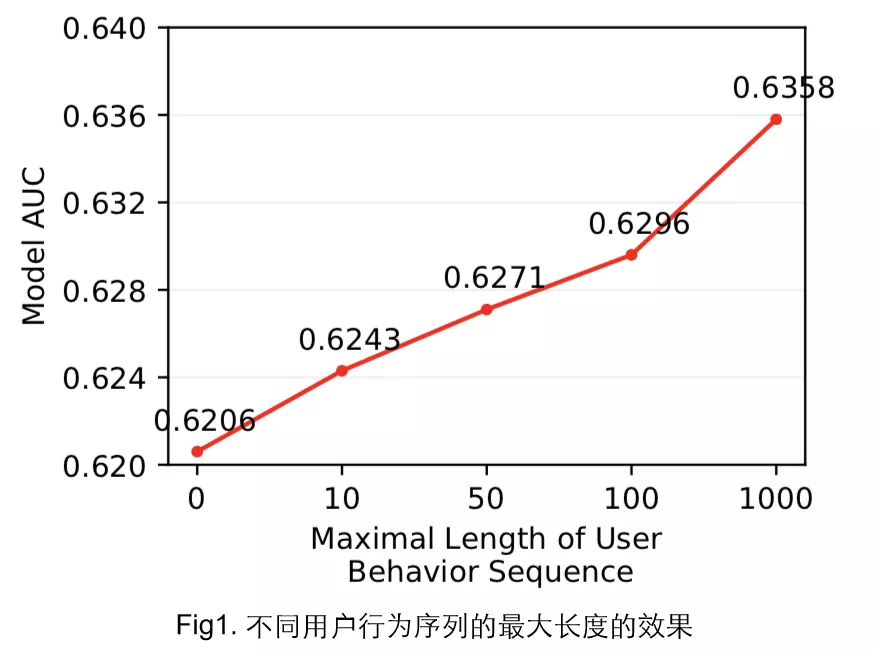
从上图中可以发现,当用户行为序列长度增加到1000时,AUC会有1.5%的提升,用户历史行为数据对ctr的预估是有很大帮助的,而且越丰富用户行为数据对ctr模型的帮助越大。
本文的主要工作:
- 提出SIM建模长序列用户行为数据,两阶段的串行的机制设计使得SIM能够更好地建模lifelong序列行为数据;
- 介绍了在大规模工业系统中部署SIM的实际经验,SIM已经部署在阿里展示广告系统上,带来了7.1%CTR和4.4%RPM的提升;
- SIM推动用户行为长度最大到达54000,比MIMN提高了54倍。
目前,对于用户行为数据的利用分为两方面:
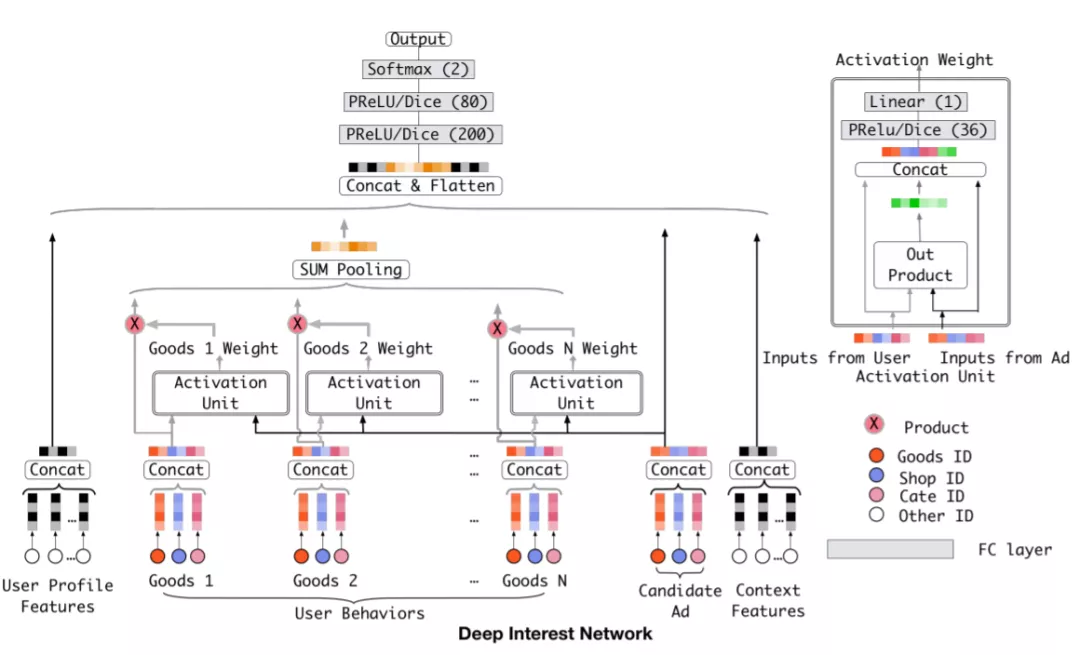
- 一种是考虑效果DIN和DIEN,优点:考虑候选广告和用户行为的关系(Attention等),使用与候选item相关的行为建模出用户对于当前候选的兴趣,即可以建模出用户对不同候选item的兴趣;缺点:用户行为不能太长,serving的性能和线上存储。
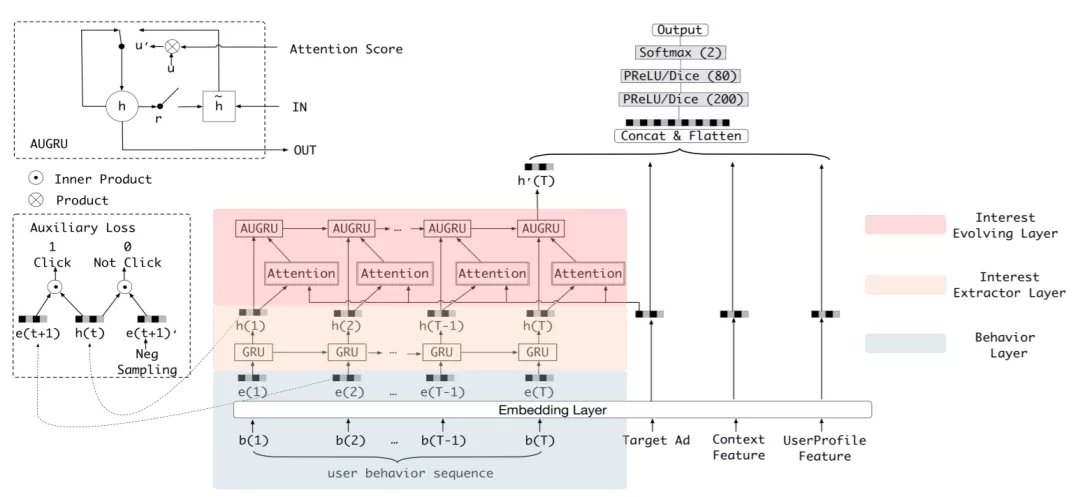
- 另一种是考虑性能MIMN,优点:将用户兴趣建模和ctr预估解耦,在用户兴趣建模方面,借鉴memory network的思路,使用两个矩阵M和S分别存储用户兴趣的信息和用户兴趣演化的信息,线上进行ctr预估时,只需要读取两个固定大小矩阵。因为兴趣矩阵可以提前计算好,所以不会对线上耗时造成较大的影响。缺点:固定大小的memory 矩阵表达信息是有限的,如果想建模更长的用户行为序列,memory-based的方法会面临表达能力有限,难以过滤噪声,建模随时间信息遗忘的问题。UIC&MIMN解耦了兴趣建模和在线CTR预估的计算,建模用户兴趣时模型无法获取和使用待预估的候选item的信息。
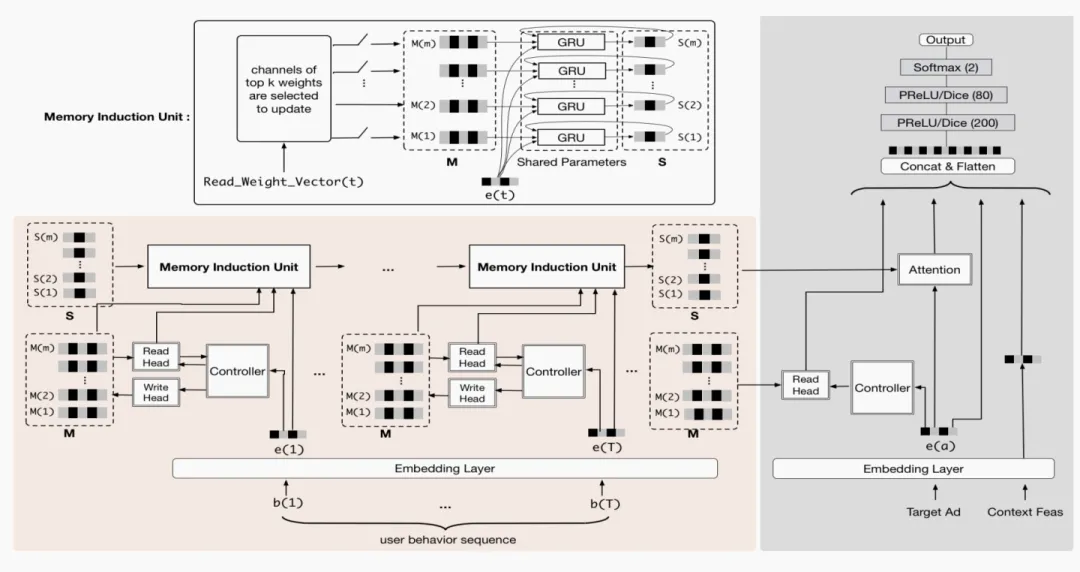
这说明如果想更准确地建模超长的用户行为,对候选item的利用是很有必要的。
模型结构
本文借鉴了DIN的思想,也就是用与候选item相关的用户行为建模用户对当前预估目标item相关的兴趣。同时又考虑到线上根据候选item直接对全序列进行搜索性能肯定是扛不住的,所以就把整个搜索过程分成了两个阶段,即General Search Unit和Exact Search Unit。General Search Unit是将长度上千的用户行为数据缩减至几百,其中的大部分计算可以离线完成,Exact Search Unit是将缩减后的用户行为进一步进行信息提取,建模出用户对于候选item的兴趣。
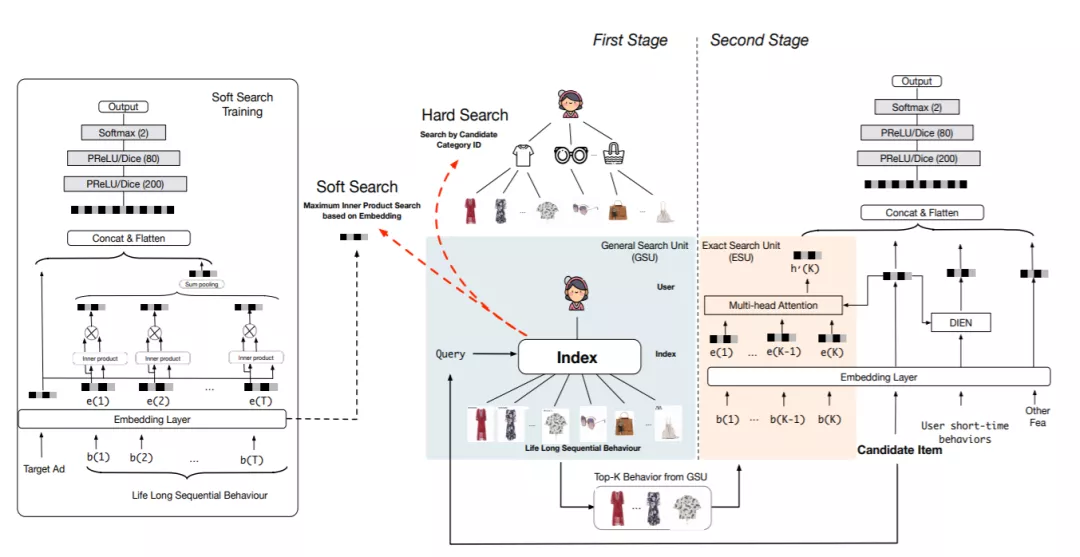
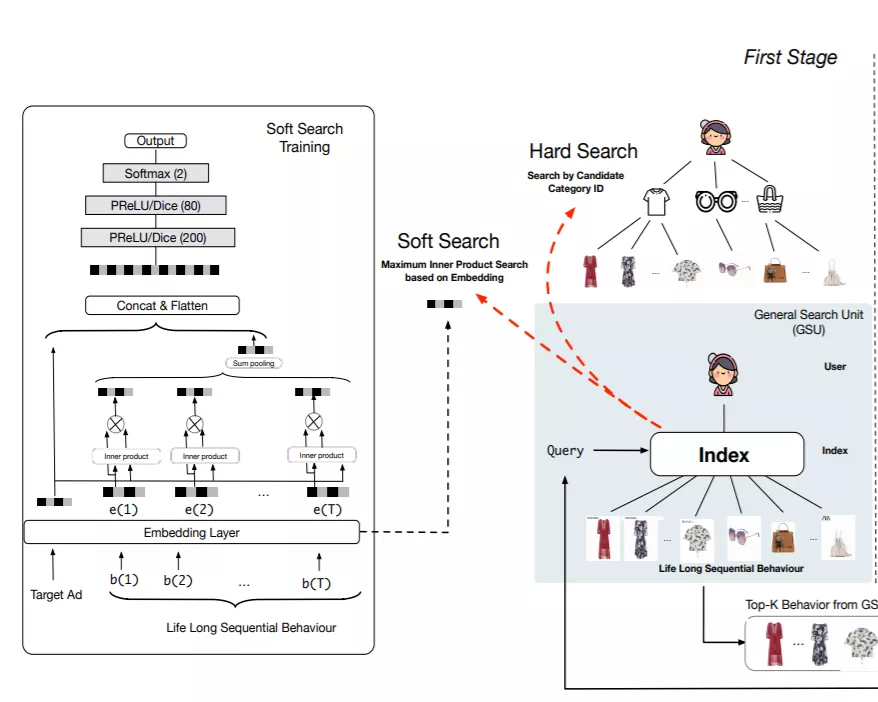
General Search Unit的两种实现思路:
- Hard Search,无参的方式。直接选出与候选item同类目的用户行为。这样做的原因是电商场景下,item天然具有层级结构,所以直接选出同类目的行为也是合理的。
- Soft Search,用参数化的方式,对用户行为和候选item进行向量化,然后用向量检索的方式检索出Top_K个相关的行为(实现方法有Maximum Inner Product Search (MIPS)的方法ALSH)。文中提到因为长期用户行为的分布和短期用户行为的分布不一致,直接使用ctr模型中,短期行为学习到的embedding矩阵,会造成一定的误导,所以对于Soft Search中需要用到的embedding矩阵要单独搭建模型,进行训练。训练数据为超长的用户行为序列,作为ctr的一个辅助任务联合训练,如果行为过长,需要随机采样。
给定用户行为集合B=[b_1; b_2; ,,, ; b_T] ,其中b_i是第i个用户行为, T是用户行为的长度。GSU为每个行为b_i计算关于候选商品的相关性分数 r_i,然后根据r_i选择Top-K相关的行为得到行为序列 B^*。hard-search和soft-search不同点是r_i的计算公式:
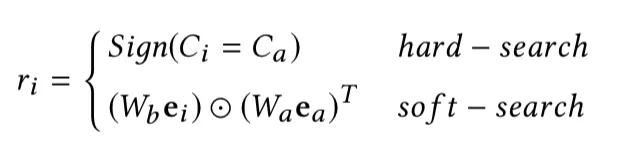
hard-search 是无参数的,只有和候选广告类目相同的用户行为数据才会被选出送到下一级进行建模。其他C_a代表了候选广告类目,C_i代表了第i个用户行为的类目。虽然hard-search是一种基于数据特征的一种比较直观的方案。但是它非常容易部署到实际工业界在线预估系统中。
在 soft-search 中,我们将用户行为序列B映射成为embedding表达E=[e_1; e_2; ……; e_T]。W_b和W_a都是模型参数,其中e_a代表了候选广告的embedding,e_i代表了第i个用户行为embedding。为了加速上万个用户行为的Top-K检索,采用基于内积的近似最近邻检索出Top_K个相关的行为,比如Maximum Inner Product Search (MIPS)。
在工业数据上,Hard Search可以覆盖Soft Search中75%的行为,线上考虑性能使用了Hard Search。
**Exact Search unit **直接使用multi-head Attention的结构对GSU中提取出的topK的用户行为进行建模,得到用户的长期兴趣的表示。因为长期行为中的时间跨度较大,文中也将历史行为与候选行为之间的时间间隔建模进来。
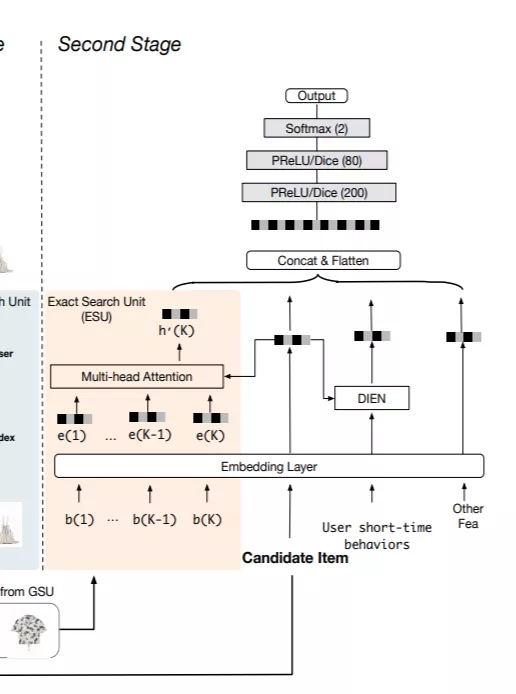

Multi-head attention
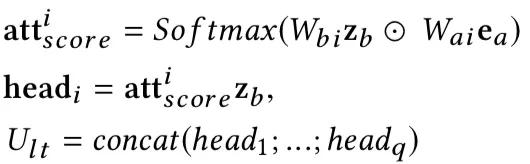
最后,其中第一阶段和第二阶段是采用交叉熵 loss 联合学习。Loss 函数如下:
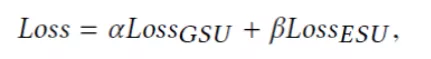
Online Serving
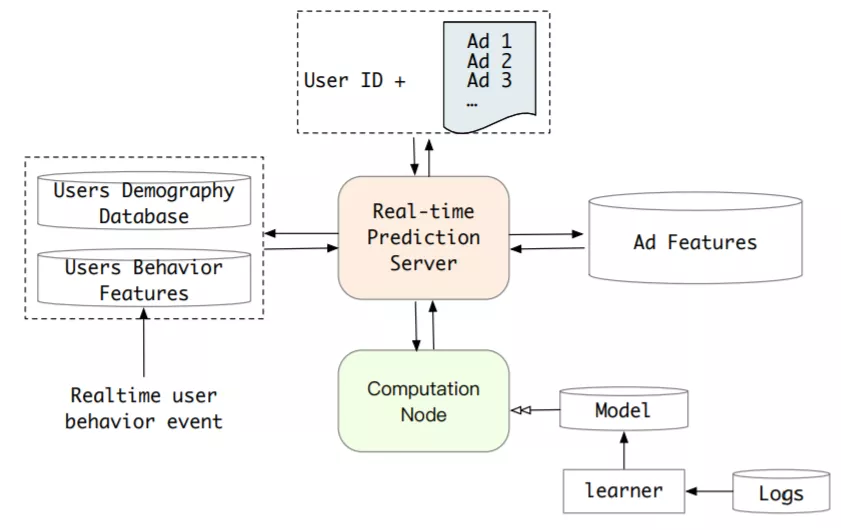
工业推荐系统和广告系统需要在1秒内处理巨量流量请求,需要CTR模型实时响应。serving耗时应该少于30ms。上图简要说明了CTR任务的Real Time Prediction (RTP) system。考虑lifelong用户行为,长期用户兴趣模型的serving在实时系统中更加困难。存储和耗时是长期用户兴趣模型的瓶颈。流量会随着用户行为序列长度线性增长。并且,在流量高峰每秒会有100万的用户请求。部署长期兴趣模型到线上挑战巨大。
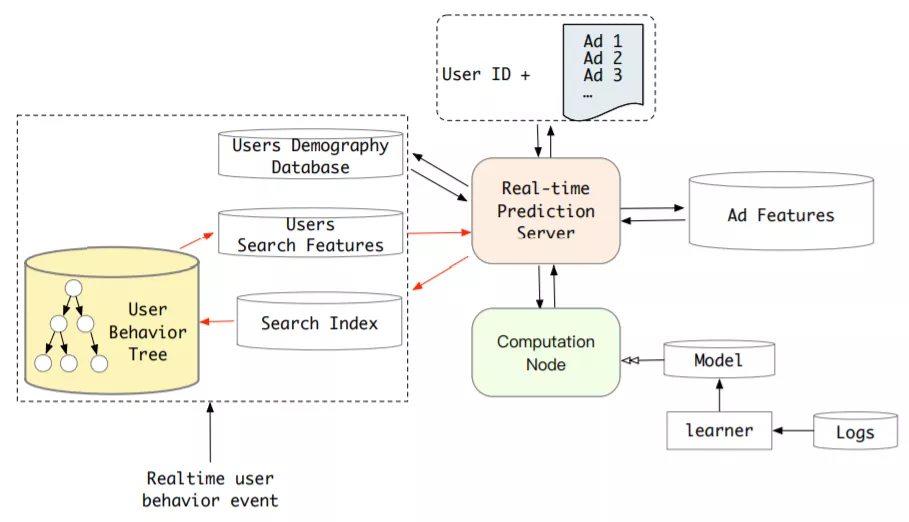
对于GSU里的两种search-model:soft-search model和hard-search model,用阿里的数据集做了大量离线实验。可以观察到soft-search model和hard-search model得到的Top-K行为极度相似,也就是soft-search得到的大多数top-K行为和目标商品的类目是一样的。这是我们场景里数据的一个典型特征。鉴于此,尽管soft-search model在离线实验中比hard-search model稍微好些,权衡收益和资源消耗,最终选择在我们系统中用hard-search model部署SIM。
General Search的选择:Hard Search选出的用户行为可以覆盖soft Search选
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%B7%B1%E5%85%A5%E7%90%86%E8%A7%A3%E6%8E%A8%E8%8D%90%E7%B3%BB%E7%BB%9F%E8%B6%85%E9%95%BF%E7%94%A8%E6%88%B7%E8%A1%8C%E4%B8%BA%E5%BA%8F%E5%88%97%E5%BB%BA%E6%A8%A1/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


