深度学习中不得不学的方法
之前已经有无数同学让我介绍一下Graph Embedding,我想主要有两个原因:
- 一是因为 Graph Embedding是推荐系统、计算广告领域最近非常流行的做法,是从word2vec等一路发展而来的Embedding技术的最新延伸;
- 二是因为已经有很多大厂 将Graph Embedding应用于实践后取得了非常不错的线上效果。
那我们今天就一起讨论一下Graph Embedding的主要做法和前沿应用。
word2vec和由其衍生出的item2vec是embedding技术的基础性方法(我在之前的文章中也详细介绍了二者的技术原理, 王喆:万物皆Embedding,从经典的word2vec到深度学习基本操作item2vec),但二者都是建立在“ 序列”样本(比如句子、推荐列表)的基础上的。而在互联网场景下,数据对象之间更多呈现的是图结构。典型的场景是由用户行为数据生成的和物品全局关系图(图1),以及加入更多属性的物品组成的知识图谱(图2)。
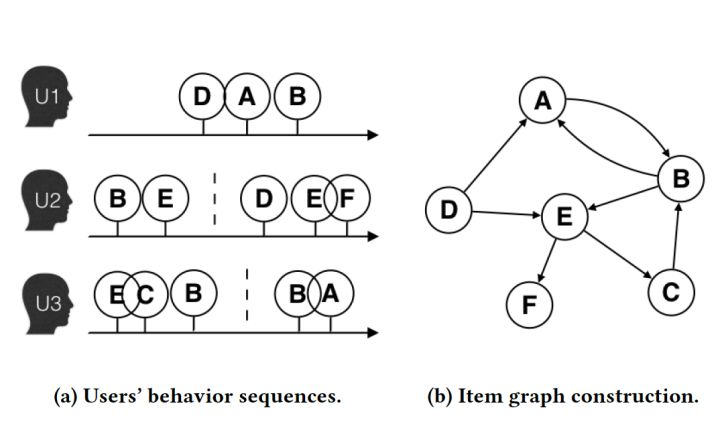
图1 由用户行为序列生成的物品全局关系图 (引自阿里论文)
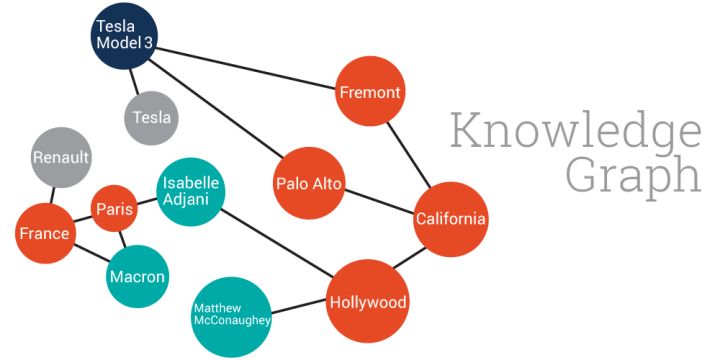
图2 由属性、实体、各类知识组成的知识图谱
在面对图结构的时候,传统的序列embedding方法就显得力不从心了。在这样的背景下,对图结构中间的节点进行表达的graph embedding成为了新的研究方向,并逐渐在深度学习推荐系统领域流行起来。
经典的Graph Embedding方法——DeepWalk
早期影响力较大的graph embedding方法是2014年提出的DeepWalk,它的主要思想是在由物品组成的图结构上进行随机游走,产生大量物品序列,然后将这些物品序列作为训练样本输入word2vec进行训练,得到物品的embedding。图3用图示的方法展现了DeepWalk的过程。
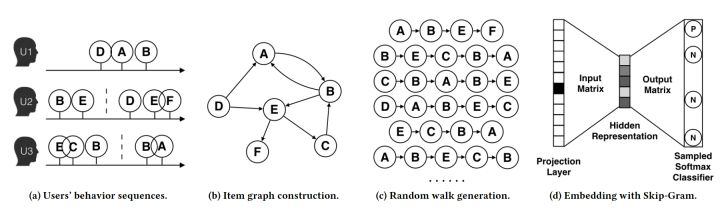
图3 DeepWalk的算法流程(引自阿里论文)
如图3,整个DeepWalk的算法流程可以分为四步:
- 图a展示了原始的用户行为序列
- 图b基于这些用户行为序列构建了物品相关图,可以看出,物品A,B之间的边产生的原因就是因为用户U1先后购买了物品A和物品B,所以产生了一条由A到B的有向边。如果后续产生了多条相同的有向边,则有向边的权重被加强。在将所有用户行为序列都转换成物品相关图中的边之后,全局的物品相关图就建立起来了。
- 图c采用随机游走的方式随机选择起始点,重新产生物品序列。
- 图d最终将这些物品序列输入word2vec模型,生成最终的物品Embedding向量。
在上述DeepWalk的算法流程中,核心是第三步,其中唯一需要形式化定义的是随机游走的跳转概率,也就是到达节点vi后,下一步遍历vi的临接点vj的概率。如果物品的相关图是有向有权图,那么从节点vi跳转到节点vj的概率定义如下:
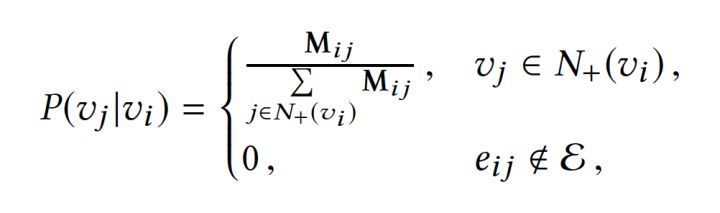
其中N+(vi)是节点vi所有的出边集合,Mij是节点vi到节点vj边的权重。
如果物品相关图是无相无权重图,那么跳转概率将是上面公式的一个特例,即权重Mij将为常数1,且N+(vi)应是节点vi所有“边”的集合,而不是所有“出边”的集合。
DeepWalk的进一步改进——Node2vec
2016年,斯坦福大学在DeepWalk的基础上更进一步,通过调整随机游走权重的方法使graph embedding的结果在网络的**同质性(homophily) 和 结构性(structural equivalence)**中进行权衡权衡。
具体来讲,网络的“同质性”指的是距离相近节点的embedding应该尽量近似,如图4,节点u与其相连的节点s1、s2、s3、s4的embedding表达应该是接近的,这就是“同质性“的体现。
“结构性”指的是结构上相似的节点的embedding应该尽量接近,图4中节点u和节点s6都是各自局域网络的中心节点,结构上相似,其embedding的表达也应该近似,这是“结构性”的体现。
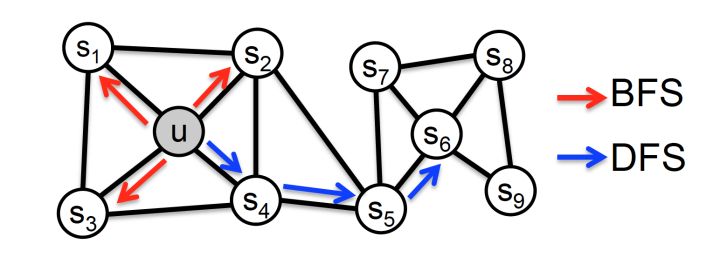
图4 宽度优先搜索(BFS)和 深度优先搜索(DFS)示意图
为了使Graph Embedding的结果能够表达网络的 同质性,在随机游走的过程中,需要让游走的过程更倾向于 宽度优先搜索(BFS),因为BFS更喜欢游走到跟当前节点有直接连接的节点上,因此就会有更多同质性信息包含到生成的样本序列中,从而被embedding表达;另一方面,为了抓住网络的 结构性,就需要随机游走更倾向于 深度优先搜索(DFS),因为DFS会更倾向于通过多次跳转,游走到远方的节点上,使得生成的样本序列包含更多网络的整体结构信息。**(通过 **
** 同学的提醒,这里其实是写反了,BFS应该反映了结构性,DFS反而反应了同质性,大家可以深度思考一下这是为什么,欢迎在评论区讨论)**
那么在node2vec算法中,是怎样控制BFS和DFS的倾向性的呢?主要是通过节点间的跳转概率。图5显示了node2vec算法 从节点t跳转到节点v后,下一步从 节点v 跳转到周围各点的跳转概率。
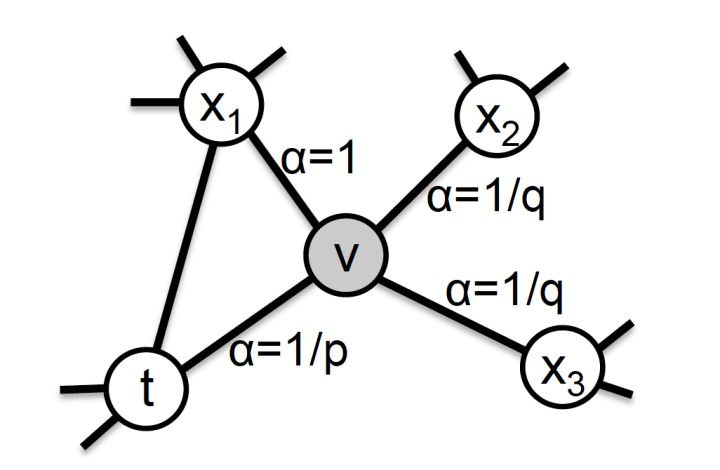
图5 node2vec的跳转概率
形式化来讲,从节点v跳转到下一个节点x的概率为
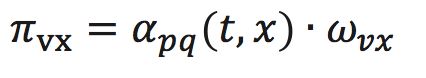
其中
 是边vx的权重,
是边vx的权重,
 的定义如下:
的定义如下:
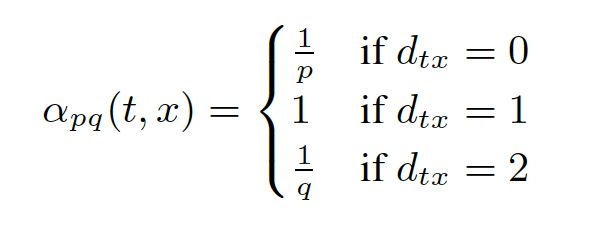
其中,dtx指的是节点t到节点x的距离,参数p和q共同控制着随机游走的倾向性。参数p被称为返回参数(return parameter),p越小,随机游走回节点t的可能性越大,node2vec就更注重表达网络的同质性,参数q被称为进出参数(in-out parameter),q越小,则随机游走到远方节点的可能性越大,node2vec更注重表达网络的结构性,反之,当前节点更可能在附近节点游走。
node2vec这种灵活表达同质性和结构性的特点也得到了实验的证实。图6的上图就是node2vec更注重同质性的体现,可以看到距离相近的节点颜色更为接近,而图6下图则是结构特点相近的节点的颜色更为接近。
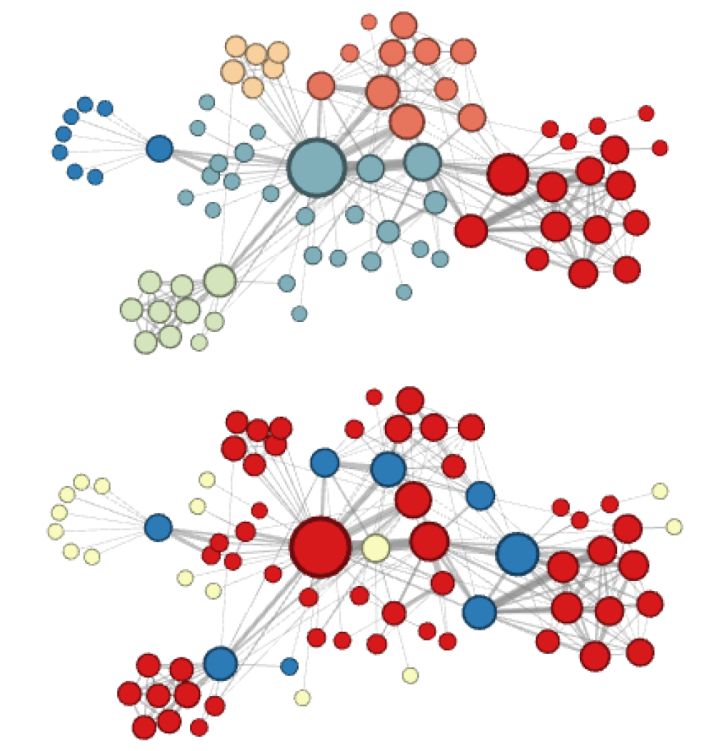
图6 node2vec实验结果
node2vec所体现的网络的同质性和结构性在推荐系统中也是可以被很直观的解释的。 同质性相同的物品很可能是同品类、同属性、或者经常被一同购买的物品,而 结构性相同的物品则是各品类的爆款、各品类的最佳凑单商品等拥有类似趋势或者结构性属性的物品。毫无疑问,二者在推荐系统中都是非常重要的特征表达。由于node2vec的这种灵活性,以及发掘不同特征的能力,甚至可以把不同node2vec生成的embedding融合共同输入后续深度学习网络,以保留物品的不同特征信息。
阿里的Graph Embedding方法EGES
2018年阿里公布了其在淘宝应用的Embedding方法EGES(Enhanced Graph Embedding with Side Information),其基本思想是在DeepWalk生成的graph embedding基础上引入补充信息。
如果单纯使用用户行为生成的物品相关图,固然可以生成物品的embedding,但是�
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E4%B8%AD%E4%B8%8D%E5%BE%97%E4%B8%8D%E5%AD%A6%E7%9A%84%E6%96%B9%E6%B3%95/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


