深度学习在同城首页推荐排序上的实践
分享嘉宾: 王连臣,58同城TEG搜索推荐部高级算法工程师
整理出品: 张劲, AICUG人工智能社区
系列分享:
导读: 行为序列化已然成为用户兴趣建模的主流方式,本次议题主要介绍序列化建模在首页推荐场景的实践,提出了适配业务特点的深度学习模型,经历了从双通道到多通道到多场景适配的升级迭代过程,通过多种行为序列通道,实现了对用户兴趣的精准刻画。
PPT下载: http://www.aicug.cn/#/docs
浏览器不支持该媒体的播放 :(
分享嘉宾: 王连臣,58同城TEG搜索推荐部高级算法工程。主要负责58APP首页推荐场景下深度学习排序模型的优化与迭代。
01 场景/挑战/兴趣建模
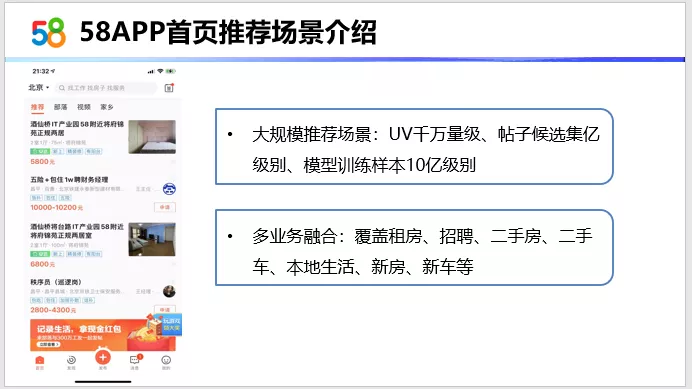
首页推荐场景是58APP最大规模的推荐场景,UV千万量级,帖子候选集上亿级别,日常模型训练样本10亿级别。首页是多业务融合的,覆盖租房、招聘、二手房、二手车、本地生活、新房、新车等多个业务。

在多业务融合场景下会面临着诸多挑战。第一个挑战就是业务差异带来的特征对齐困难。比如帖子属性信息的差异,租房和二手车这些属性信息差异比较大的情况;用户兴趣业务差异,比如用户租房和用户买车兴趣周期是不一致的;样本中帖子的特征与用户信息特征无法对齐的问题;还有反馈特征,比如历史CTR,由于我们的多业务特点,就会导致反馈特征的取值范围差异比较大。上线的效果实际上也不是很理想。
第二个困难,是多业务融合特征工程流程复杂,逻辑复杂。部分特征需要针对不同的业务维护特有的数据流程。比如说用户兴趣构建,需要针对不同的业务分别开发,开发、维护代价特别大。还有业务特定的特征工程逻辑,复杂度比较高,比如匹配交叉特征。
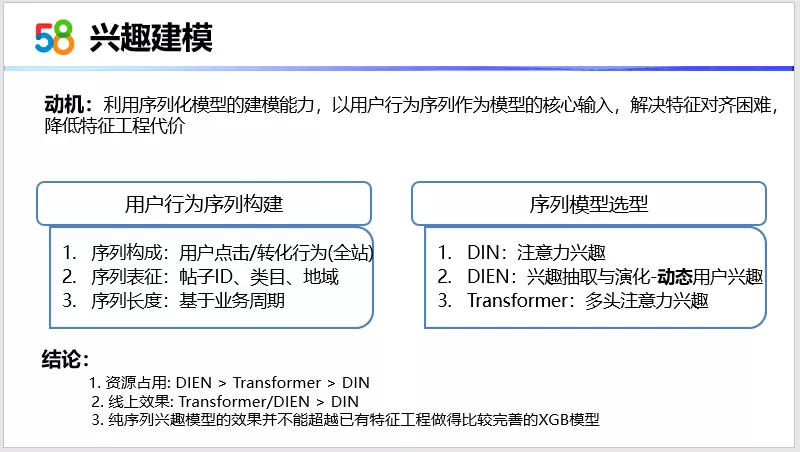
为应对这些挑战,即是特征对齐困难,以及特征工程的代价,我们利用序列化模型的建模能力,以用户行为序列作为模型的核心输入来解决这些挑战。下面介绍下我们的用户行为序列是如何构建的。
首先是序列的构成,我们使用了58APP全站的用户点击以及转化行为来构建序列。在序列表征上我们使用的是帖子ID、类目ID以及地域ID,最后使用的序列长度,是基于业务周期做线上实验,最终确定的。
在序列模型选型上,我们是使用了DIN模型,DIN模型是基于attention机制来计算,待排序帖子与用户历史行为之间的相关性,通过相关性就可以对它进行加权求和,得到一个最终的用户兴趣的表示。第二个模型就是DIEN模型,DIEN模型分为两层,第一层是兴趣抽取层,第二层是兴趣演化层,这篇论文提到通过DIEN模型的兴趣演化层来捕捉动态的用户兴趣。第三个模型就是transformer,transformer主要组成部分实际上是多头attention以及残差,及后面的前馈神经网络。通过多头attention来学习待排序帖子和用户历史行为之间的相关性,再来计算用户兴趣,实际上transformer,可以为每个时序输出一个向量表示,我们可以对它进行求和,也可以对它进行展开,这是可以进行线上实验的。
总结的结论,第一是资源占用,DIEN大于transformer,transformer大于DIN。第二个是线上效果,transformer和DIEN差不多,但都超过DIN。DIEN这个模型,可以为动态的用户兴趣建模。但是结合58同城的用户特点,其实用户的动态性不是特强。所以我们在后续的优化中没有考虑用DIEN,而是考虑了模型结构更具备扩展性的transformer。最后一点,纯序列兴趣模型其实是不能超越已有特征工程做的比较完善的XGB模型的。初期实验的阶段,实际上只是单纯用了用户行为序列,基于这些实验,我们在首页进行了双通道深度兴趣模型的应用。
02 双通道深度兴趣模型的应用

双通道深度兴趣模型分成三部分,第一部分是模型结构,然后是离线、在线性能优化,最后是线上效果优化。
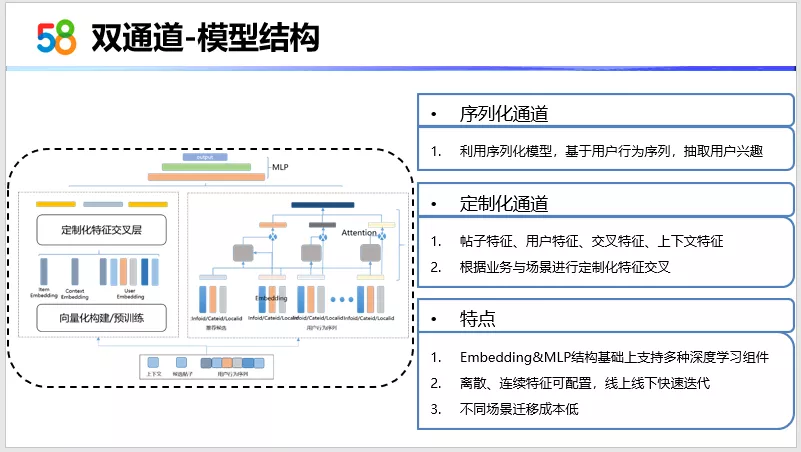
双通道模型的结构可以从左图来看,从下往上依次是输入层,embedding层以及双通道,最终是 MLP。双通道左边是定制化通道,右边是序列化通道。先说序列化通道,序列化通道就是刚刚提到的 transformer。我们基于transformer抽取用户兴趣。定制化通道,是将帖子的一些基础特征以及用户的特征,还有交叉特征、上下文特征来做输入。因为这些特征是我们之前在做特征优化过程中积累下的比较重要的特征,在线上效果也已经验证,并且结合了具体的业务。所以将这部分特征放在了定制化通道里面。定制化通道在我们后期的一个新的优化方向,是会根据业务与场景进行定制化特征交叉,来最终实现一个多场景的适配。因为我们的推荐场景是很多的,比如58 APP首页推荐场景,租房大类页,以及租房详情页这样的推荐场景。这些推荐场景下的样本相比首页的数据小很多。首页是多业务融合,它是包含租房这些业务的,所以说我们后期会利用首页大规模的样本数据以及融合其他场景下的数据来训练这个模型。
最后介绍下模型的特点。这个模型其实以embedding层以及MLP结构为基础,支持了多种深度学习组件。这些组件就是刚才提到的DIEN以及transformer,还有在基础特征层面,我们的离散特征以及连续值特征都是可以配置的。这样在上线之前的大量实验就可以快速完成,线上也可以快速进行模型的迭代,不同场景之间的迁移成本也会低一些。后期在定制化通道部分我们实现了场景适配后,就不再需要模型的场景迁移了。
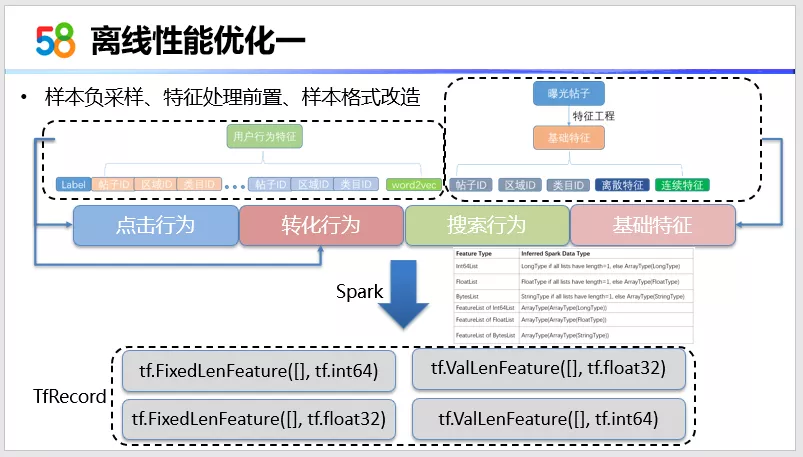
在上线之前需要先把离线训练性能以及排序服务的线上性能优化好。我们先看离线性能优化。第一点,我们通过在构建样本的时候,先要将样本的量级减小。因为刚才提到首页推荐场景的样本量可以达到10亿级别,我们通过负采样。具体负采样,可以通过简单的随机负采样或者在真曝光数据上进行指定比例的正负样本比例的采样来实现。
再一个就是特征处理前置,我们会把所有的特征处理逻辑,比如基础特征以及行为特征,在MapReduce中实现。
然后是样本格式的改造,将最后的样本统一改成TfRecord的格式,因为TfRecord的格式是 TensorFlow支持的一种IO性能比较好的数据。具体在转换 TfRecord数据的时候,我们使用的是Spark。这里列出来了一些Spark和TensorFlow支持的数据格式。
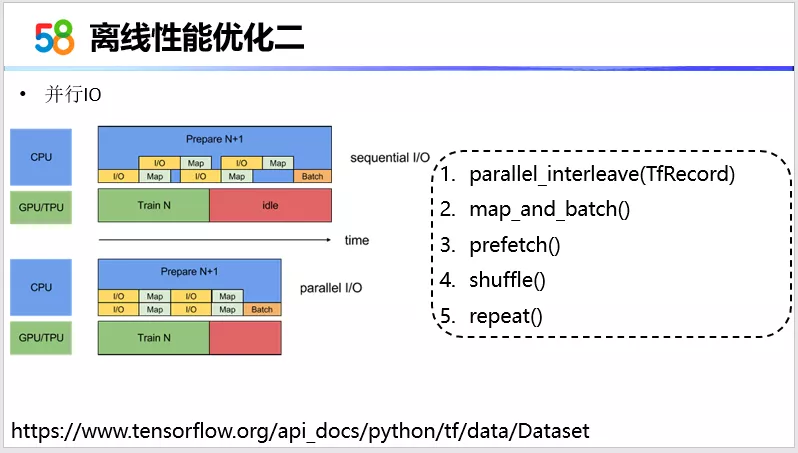
我们的目标是数据IO和训练过程的并行,实际上我们不需要自己手动去做太多的东西,因为TensorFlow本身就提供了Dataset API组件。在使用了 dataset API优化之后的结果,实际上就是样本I/O的过程以及转特征转换。包括准备数据,这部分可以在CPU部分可以并行执行。这样就可以做到CPU并行处理数据和训练模型。具体的操作上实际上就是使用了右边列出来的这5个API。
第一个,是并行读多个样本。我们在存数据的时候,实际上是使用了分块存储。第二个,是使用组件的时候要按照顺序来做,效果肯定是能够达到预期的。
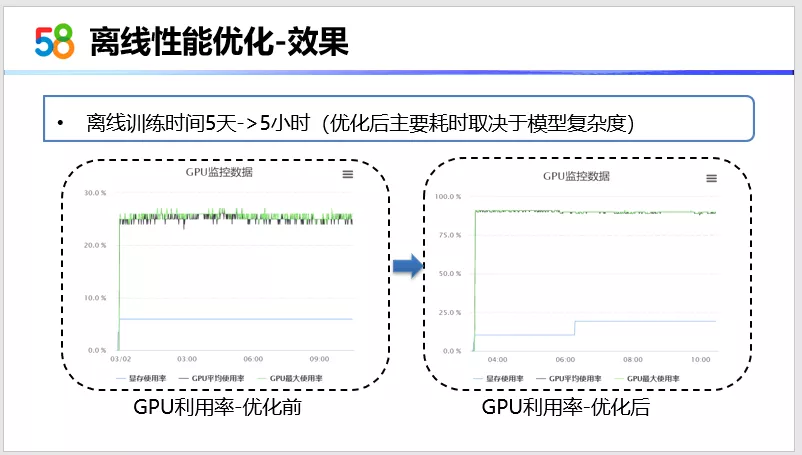
从GPU的利用率上来看,优化前使用率是低于30%的,在优化后GPU利用率可以达到90%以上,最终整体在首页的这种大规模数据场景下,我们的训练时长可以从原来的5天左右优化到现在的5个小时。后期如果还要继续优化离线训练模型的性能,它的瓶颈不在I/O了,而在于这个模型的复杂度,如果还要继续优化,可以考虑分布式训练。
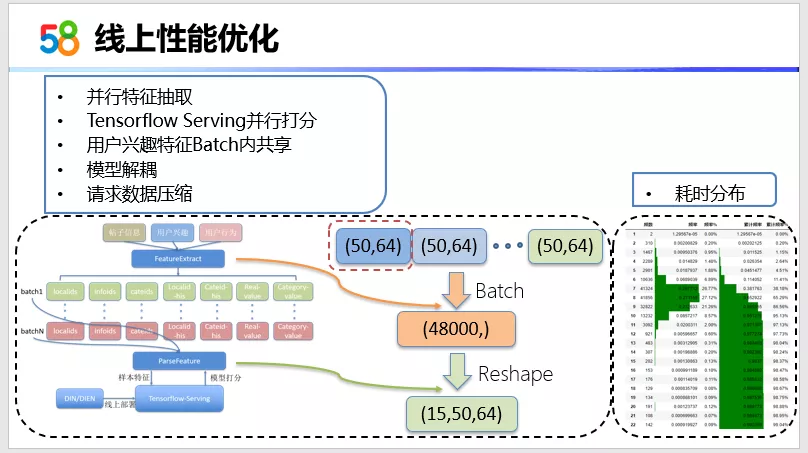
线上的性能优化,前两点是并行特征抽取以及并行打分,线上会将排序请求里面的多个帖子并行分成多个Batch,来请求TensorFlow Serving。在模型打分部分,实际上线上和离线是一个道理。我们在离线训练的时候,实际上是通过Batch数据来训练模型,线上打分的时候,也是要把batch数据传给它,就实现了真正打分的并行。
第三点是用户兴趣的特征。因为在线上和线下用户特征是不一样的。离线的时候是把样本打散的,在线上每一个请求,实际上用户特征部分是相同的。所以要对它进行Batch内共享,这样也能提升网络性能。
第四点模型的解耦。因为我们用到深度学习来训练模型,刚才还提到了一个方案,用帖子ID。在向量化召回,也提到了我们7天的样本数据中,帖子量就可以达到5000万,我们要放到模型里来直接训练 ,随着向量纬度的增加实际上这个模型达到几G甚至十几G。但是我们在线上去预测的时候,这个大模型Tensorflow Serving不一定能够加载,所以要进行模型解耦。
第五点是请求数据的压缩。在模型解耦之后,我们的用户行为部分的特征,实际上在向量维度上就不会再局限于128维或256维这样的维度。我们可以进行长度的一个实验。随着用户行为长度的增加,这个请求数据会越来越大,因此在考虑到线上性能的时候,我们对它进行了数据压缩。最终我们的耗时分布大家可以从右图看到,有95%的请求是低于10毫秒。左边这半部分图是我对刚刚说的请求并行、打分并行的一个图解,后期大家可以看一下。
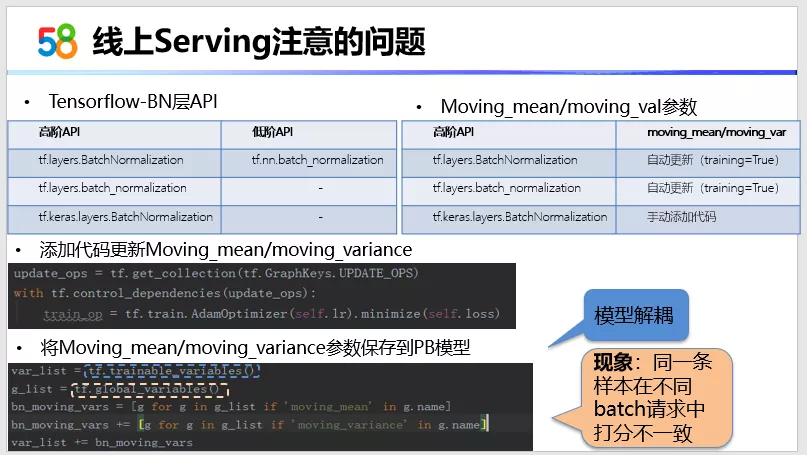
在线上服务的时候,我们其实离线用的是TensorFlow来训练,线上预估的时候,实际上是用到TensorFlow Serving。模型必须是 PB格式的模型,在用到这个模型的时候要注意一些参数的保存。
前面介绍过BN层在模型中的重要性,我这里列举了TensorFlow里面的关于BN的一些 API以及它的均值和方差参数是否自动更新这样的一个列表。大家可以参考一下。假设你使用的这个版本,它是不支持这两个参数的更新,你需要在代码里面添加上这两个参数进行更新。即使是更新了之后,还有另外一个问题就是我们需要将这两个参数保存到最终线上服务的模型里面。假设不保存,就会出现同一条样本在不同的Batch请求中打分不一致。那将这两个参数放到PB模型是怎么来做呢?实际上,因为这两个参数并不是训练得到的,它其实是在全局的变量列表里面,我们可以在黄色的框框里面找到它。刚才提到的模型解耦,实际上是在模型里面训练的一部分参数矩阵,所以我们实际上是在这个训练的参数列表里面可以找到相应的参数名,然后把它给去掉,实现模型的解耦。
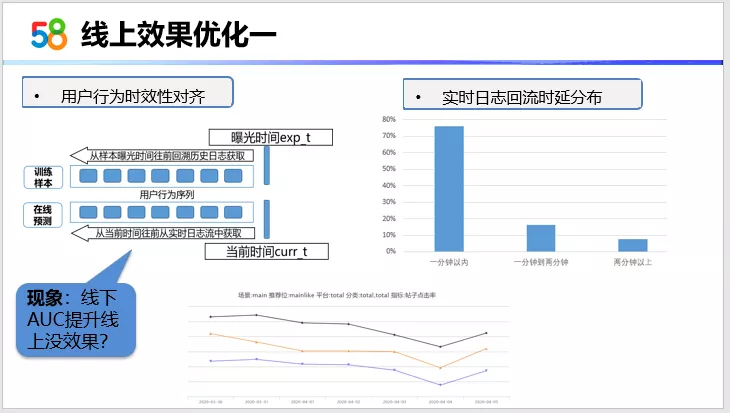
看一下离线以及在线的性能优化,有了前期的工作以后,我们就开始看这个线上的效果优化。
第一点就是用户行为的时效性对齐。离线,先说一种现象,线下在使用到用户行为序列之后,AUC是提升的,但是发现初期上线之后,线上效果不明显。分析原因,我们之前的一些基础特征实际上是对齐的,现在唯一加的就是用户行为序列这部分。肯定是这一部分,没有做到线上线下对齐。然后我们分析了线上的实时日志,发现有低于10%的帖子,用户行为保存时长超过了两分钟。对离线以及在线的用户行为序列部分,用两分钟来截断这个行为,一开始我们训练的时候离线样本是用曝光时间戳来截取用户行为的,是比较精准的。现在既然还未达到真正的实时用户行为,我们就对他进行了一个分钟级的截断。最终的效果是可以通过上图这条黑线看到明显的提升效果。这其实就是强调线上线下的特征对齐。
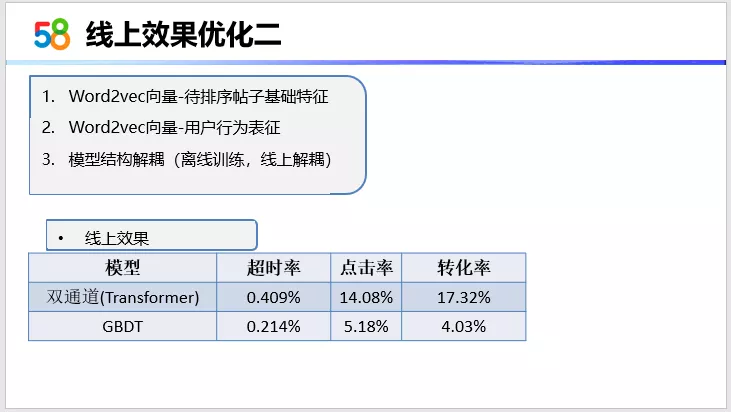
第二点优化就是Word2vec向量。这个向量在刚刚的向量化召回里面已经讲到我们如何来训练,如何来优化。在排序的这个模型上其实是可以直接来使用的。具体使用方式有两种,第一种将训练好的Word2vec向量作为待排序帖子的基础特征。第二种是将Word2vec向量作为用户每一个行为的表征,直接喂给模型。第二种其实就是刚刚说的模型结构解耦。模型结构解耦也有两种形式,第一种是通过预期Word2vec或者说其他预训练方式实现,再一个是我们通过将所有的用户行为放在模型中来进行一个训练,这两个过程。
在我们线上实验的排序效果来看,第一种是最优的,就是将训练好的 Word2vec向量作为待排序帖子的基础特征来使用,线上点击率大约有2%的提升。最终我们经过以上优化得到的一个线上效果。在双通道模型,我们现在是使用的transformer来构建的,超时率有千分之4,点击率是有14%的提升,转化率有17%的提升。
03 多通道深度兴趣模型的创新

在进一步优化过程中,我们结合58的业务进行了思考,提出了自己的模型,多通道深度兴趣模型。下面先介绍下序列化兴趣模型的优化思考,再讲下多通道深度兴趣模型的模型结构,以及最终的一个离线/线上效果。
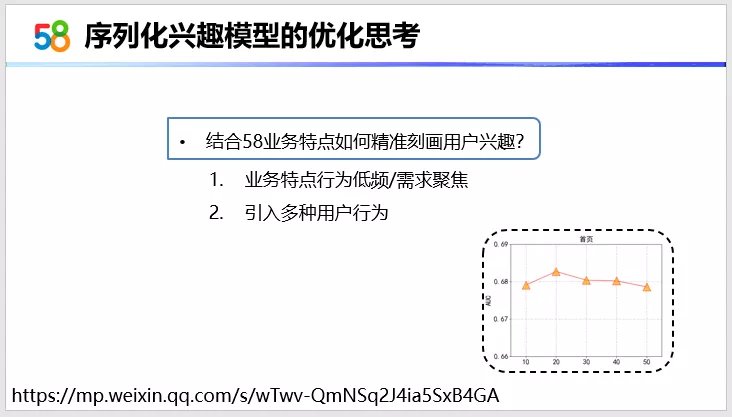
刚才提到的DIN、DIEN以及Transformer三种模型,前两个模型实际上是阿里提出来的,他们在后期的优化过程中,做了很多行为序列扩长的实验。比如说有一个模型是SIM模型,是基于搜索待排序帖子与用户历史行为相关的帖子,再计算待排序帖子与这些行为之间的相关性,达到扩长线上线下用户行为特征的目的。我们也在首页数据上进行了离线实验,看一下右下角的AUC变化,其实是在序列长度增长的这一个过程中发现AUC其实是有小幅度下降。所以在扩长用户行为的这个方向上我们是行不通的。我们分析了首页的业务特点,58的用户行为是低频的,需求是聚焦的,比如用户这一段时间租房,或是找工作,所以既然深度上我们无法进一步优化,那我们在广度上引入了多种用户行为序列。
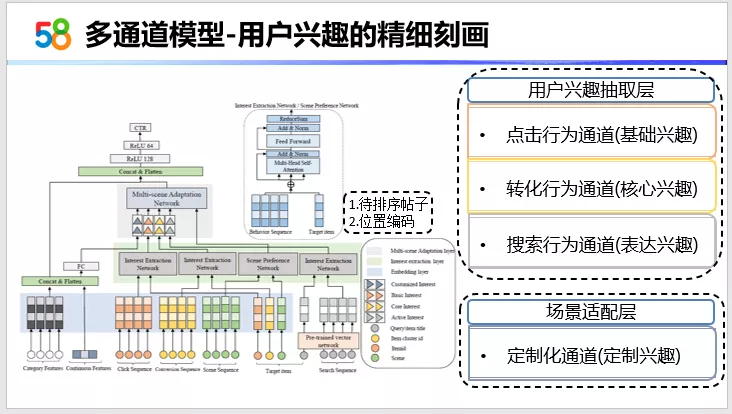
看下我们现在首页的多通道深度兴趣模型。从左下角的模型结构来看,最下边是输入层,往上依次是 embedding层,兴趣抽取层,场景适配层。这个模型的基础组件,实际上是用到了transformer。在这用到transformer的时候,先提两点,一个是待排序帖子它要放的位置。我们是通过transformer来学习,待排序帖子和用户历史行为之间的相关性的,但是transformer的结构,多头attention实际上基本结构是self-attention。而self-attention它是无法计算行为之间的位置相对关系的。基于这一点,我们要先加入一个位置编码,我们在使用的时候并没有使用到《Attention is All you need》论文里面的经过三角函数来固定相对位置编码的方式。我们使用的是为每一个用户行为的位置做一个可训练的位置编码。刚说的待排序帖子实际上是我们要计算相关性,所以要把待排序帖子放到用户的行为序列里面,这样它就可以通过self-attention学习到它的相关性。
我们看一下模型的兴趣抽取层。兴趣抽取层实际上是包含了三个通道,点击行为通道,转化行为通道以及搜索行为通道。转化行为通道,体现了用户的进一步交易的意图;第二个就是搜索行为通道,搜索行为通道是用户主动在我们平台去搜索的行为,这是用户主动表达的兴趣。这两部分实际上是相当重要的,所以在这一步的优化过程中,我们加入了多个通道来学习用户兴趣,最终我们要做到的是对用户兴趣的精细刻画。
最后一层是场景适配层,场景适配层是刚才提到的定制化通道里面的事情,定制化通道除了用到了基础特征,还要做到的是场景的适配,这里先不展开了。
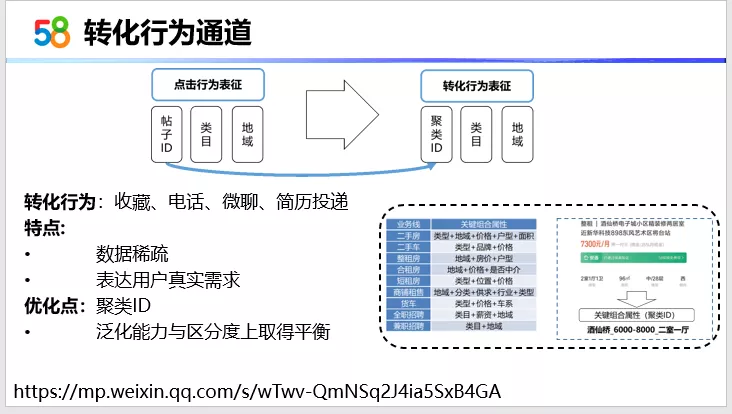
转化行为通道,我们使用的是用户的收藏、电话、微聊,以及简历投递这样的行为。这样的行为有什么特点?对比点击行为来说,它的数据更加稀疏,但是转化行为却表达了用户的真实交易意图。在具体的表征方式上,与点击行为是不同的。我们引入了聚类ID的概念,具体的做法实际上是通过业务帖的关键组合属性来表示。比如右边列的图,这个图实际上是一个租房的帖子,我们用的关键组合属性就是地域-酒仙桥,房价-6000~8000,户型-两室一厅。这样在表征上做到了泛化能力与区分度的平衡。因为如果转化行为只使用到类目以及地域ID ,它在区分度上是相对比较差的。而使用帖子ID,它的区分度太高了,线上的效果实际上不好。这里列出了一个链接,是之前我们组长分享的一些内容,大家可以通过这个链接去看相关的更详细的内容。
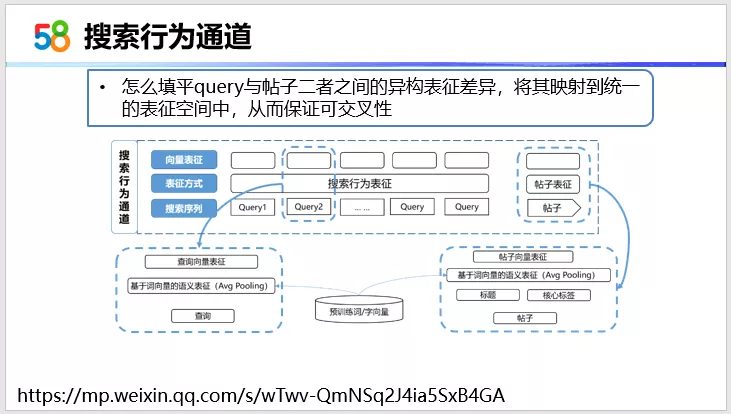
搜索行为通道是用户的主动搜索行为,这部分考虑的关键点是如何填平用户的搜索与帖子二者之间的异构表征差异。因为用户搜索是一些关键词,我们如何将其映射到统一的表征空间,从而保证在transformer模型里面的可交叉性。
看一下我们具体是如何做的。在用户的历史行为部分,这些关键词我们使用的是预训练,用预训练词向量来进行一个平均词化的表示。这个地方我们没有用到LSTM之类的语言模型,因为如果加上语言模型,会增加模型的复杂度。我们使用的是平均值化。在帖子这部分,我们使用的是标题以及核心标签来表示。为什么不使用标题而使用标题和核心标签的组合呢?因为标题里不一定包含了用户搜索的关键词。比如说酒仙桥,标题里面不一定出现,所以我们将酒仙桥、2室1厅,这样的核心标签加入到标题里面,进行帖子的向量表示,最终消除了用户的搜索行为与帖子的表征差异,就可以学习到用户的一个主动表达兴趣。
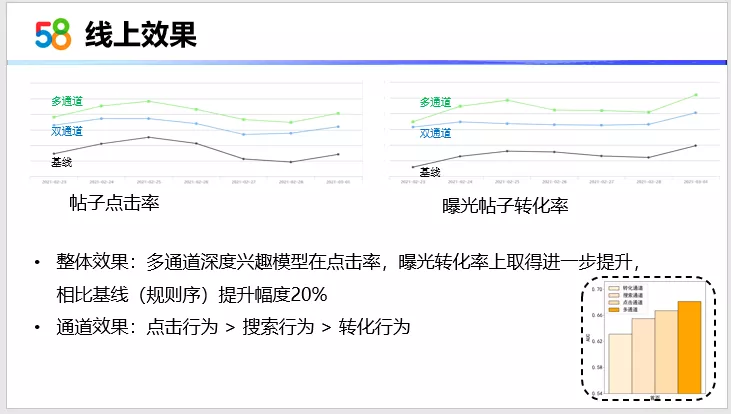
最后看一下整体的线上效果。在双通道的时候,我们实际上也做到了一个最优的效果。在继续的优化过程中,多通道在点击率以及曝光转化率上都取得了进一步的提升。相对基线,这个基线指的是规则序,提升的幅度有20%。在通道效果上,右边列出了一个离�
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E5%9C%A8%E5%90%8C%E5%9F%8E%E9%A6%96%E9%A1%B5%E6%8E%A8%E8%8D%90%E6%8E%92%E5%BA%8F%E4%B8%8A%E7%9A%84%E5%AE%9E%E8%B7%B5/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


