腾讯技术与推荐技术在腾讯浏览器的应用
口述 | 徐羽
整理 | 王强
在 AICon 全球人工智能与机器学习技术大会(2021)北京站 上,腾讯信息平台与服务线 CTO、PCG 事业群推荐与 AI 中台负责人徐羽带来了主题为《Al 与推荐技术在腾讯 QQ 浏览器的应用》的分享,详细介绍了 QQ 浏览器近年来在 AI 推荐技术方面走过的技术旅程。本文由 InfoQ 根据徐羽的演讲内容进行整理,希望对你有所启发。
 腾讯信息平台与服务线 CTO、PCG 事业群推荐与 AI 中台负责人徐羽
腾讯信息平台与服务线 CTO、PCG 事业群推荐与 AI 中台负责人徐羽
面向超大规模用户群体的推荐技术是近年来 AI 落地的热门场景之一。在国内,腾讯是较早大规模实践 AI 推荐技术的头部厂商。腾讯旗下的 QQ 浏览器应用月活用户超过 4 亿,过去几年来在 AI 和推荐技术方面经历了三次大规模重构和迭代,其实战经历具有很高的参考与学习价值。
QQ 浏览器月活用户超过 4 亿,是典型的超大规模用户群平台产品。QQ 浏览器用户群体分布与中国互联网用户群体分布相似,且用户日均使用次数较多,能够为推荐系统提供高质量的大样本数据集,为许多形态复杂、内容多样的推荐模型构建基础。
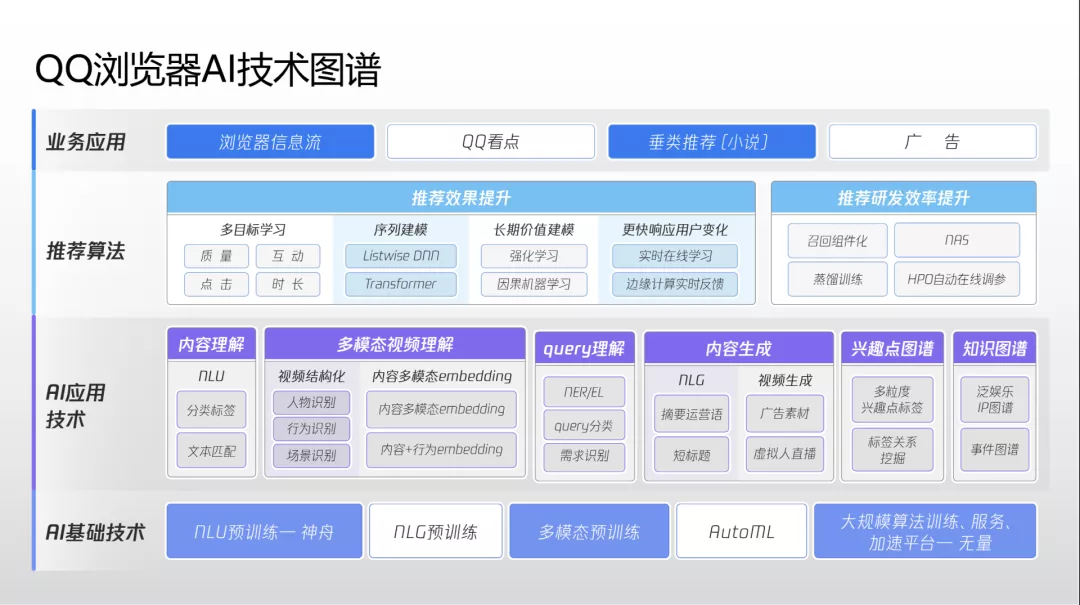
QQ 浏览器推荐系统架构
在 QQ 浏览器中,推荐算法应用的主场景是信息流。信息流主 feed 是图文、短视频、小视频混合形态。用户点击图文会进入详情页,点击竖屏小视频会进入小视频沉浸式页面,点击横版视频会进入短视频沉浸式页面。
在 2015 年之前,腾讯推荐系统大多为偏单目标和浅层的机器学习模型。2015 年微软提出了 DSSM 双塔召回模型,2016 年谷歌提出了 Wide&Deep 模型,之后腾讯开始大规模使用隐性特征做召回和排序,大大增强了推荐模型的泛化能力,一定程度缓解了推荐系统中饱受诟病的信息茧房问题。2018 年谷歌发布 MMOE 模型后,腾讯在 2020 年也发布了自研 PLE 模型,令推荐模型可以同时做多个目标。最近腾讯还在积极探索 AutoML 应用,希望使用超参数为模型自动化寻参。
纵观 QQ 浏览器整体推荐架构,从下往上来看,下层要计算的数据更多,负责将尽可能多的内容筛选出来向上层传递;上层模型更加复杂,特征更加精细化,负责尽可能给出最优排序结果。目前各个层面都有新的技术趋势和演进,其中召回层面正在引入更多图模型召回、更多常序类召回;排序层面正在引入更多多模态特征、长 session 级别特征;多目标层面纳入了点击率、时长、互动等目标,希望实现更充分的融合;混排层面,QQ 浏览器需要在每次用户刷新后决定新页面中显示的图文、短视频和小视频的比例,现在团队在使用强化学习技术处理相关排布,希望争取能够让系统获得最大奖励。
该架构在边缘计算方面也有创新。QQ 浏览器终端有小排序模型,是云端和终端联动模型。用户在沉浸式视频流中看视频时,终端模型会实时将用户反馈数据上传云端,云端根据当前视频完播率、关注度等数据调整后续视频排序,为用户在下次刷新时推荐更符合浏览兴趣的视频。
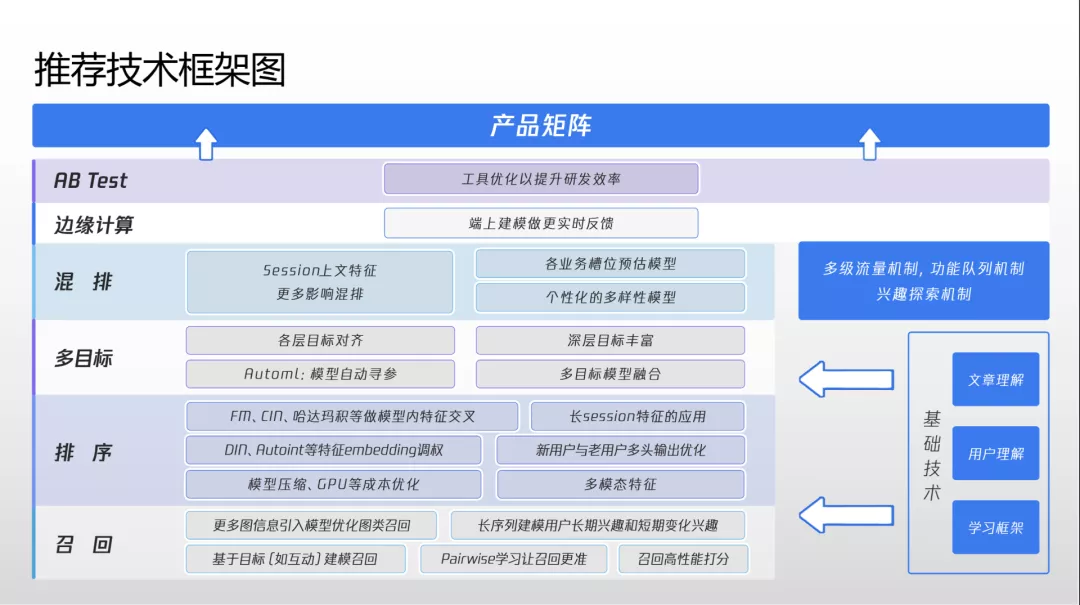
召回模块
该推荐系统召回模块分为显式召回和隐性召回。隐性召回如今占据主曝光量 90% 以上,是最重要的召回方式。隐性召回涉及算法模型较多,其中对曝光量影响最大的两种分别为 ICF(基于物品的属性召回)与 UCF(基于用户序列的召回)。
ICF 方面,腾讯早期使用了经典的关联召回,其实现简单,效果尚可,但缺乏物品相似度计算,用户体验欠佳。关联召回要求每个物品有较多用户行为才能给出较准确计算结果,很难处理好系统中的新到达内容,更倾向于推荐热门商品。
为此团队引入 NLP 中经典的 Word2vec,以用户观看减肥视频为例,Word2vec 能够关联推荐健康食品相关视频,这样在提升用户体验时显著提升了点击率。针对物品冷启动问题,现在整个召回模型使用 GraphSage 图模型算法结构。该结构要更多考虑图模型中边的信息与权重,与每个节点的特征信息。GraphSage 能够在物品没有积累很多用户行为的情况下,计算出非常准确的 Embedding,方便召回。
例如用户观看主题为深圳看海的短视频后,两个创作者上传了杭州森林、昆明田野的视频。过去的 ICF 召回无法对这样的新内容进行有效推荐,但 GraphSage 可以准确计算其 Embedding,实时向用户推荐。这一改进不仅提升了推荐效率,还有助于平台建设更良好生态,更好地扶持新创作者。
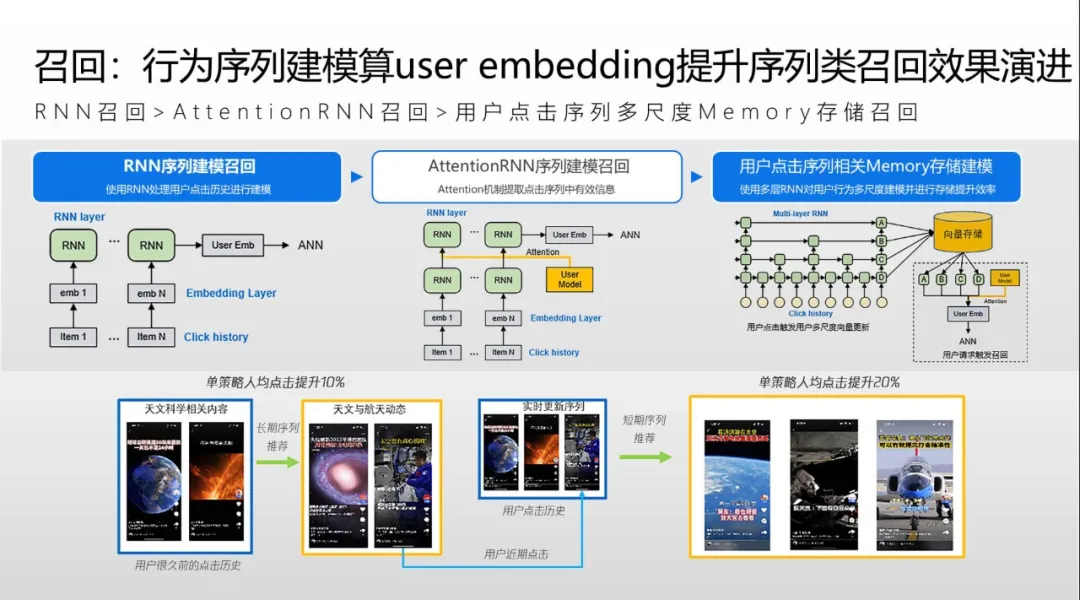
UCF 召回方面,团队使用了经典的 RNN 召回。在演进过程中,团队加入 Attention,将用户点击作为输入,算出每个用户的向量,结合物品向量计算相似度以进行召回。但 RNN 模型是串行计算方式,只能计算用户过去几十次,最多一两百次的行为;而平台很多老用户使用 QQ 浏览器很多年,行为积累几千甚至几万之多。针对这一方面需求,团队将模型升级为多层 RNN 的 Memory 的存储建模,模型中有非常多层 RNN 网络,每一层代表用户不同时间的序列,如有些层代表用户永久点击,有些层代表用户长期点击,有些层是近期点击,等等。每层网络中间存储和更新计算均不相同,从而最大化节省存储空间和提升推理速度。经过这样的改进,系统得以做到网络线上实时推理,同时召回用户永久兴趣、长期兴趣、中期兴趣和短期兴趣,从而大幅提升用户体验,使人均点击率提升 20% 以上。
排序模块
排序模块的精排层是特征最多最复杂的模型结构。团队早期使用 LR 模型,泛化能力相对较差。之后团队演进到 Wide&Deep 模型,泛化能力大大增强,但这种模型缺乏特征之间的交叉和融合方案。
最近团队将模型演进到名为“多种算法模型融合多任务学习”的排序模型。模型最下层有用户特征、物品特征和多模态特征,从中生成一些 Embedding 向量。之后对向量调权,做 Embedding Reweight;再使用 FM、CIN 等方式对 Embedding 特征做高维度交叉。模型中间是专家网络层,之前使用类似谷歌 MMOE 的实现,现在则转用腾讯内部发布的 PLE 模型。PLE 模型中,除了每个目标有自己单独的专家网络之外,还共享了一些专家设计,相较 MMOE 模型有更明确的效果。
模型最上层引入分塔技术,该技术与业务场景和使用行为高度相关。在浏览器首页,新用户和老用户的行为有所不同,因此新用户和老用户会各自单独建模,分两个塔,各有自己的输入参数以提高效果。以视频播放场景为例,团队发现短视频、长视频和中视频的物理 Label 分布不一样,所以在这个层面上按照视频物理时长做分塔切片可以提升推荐效果。
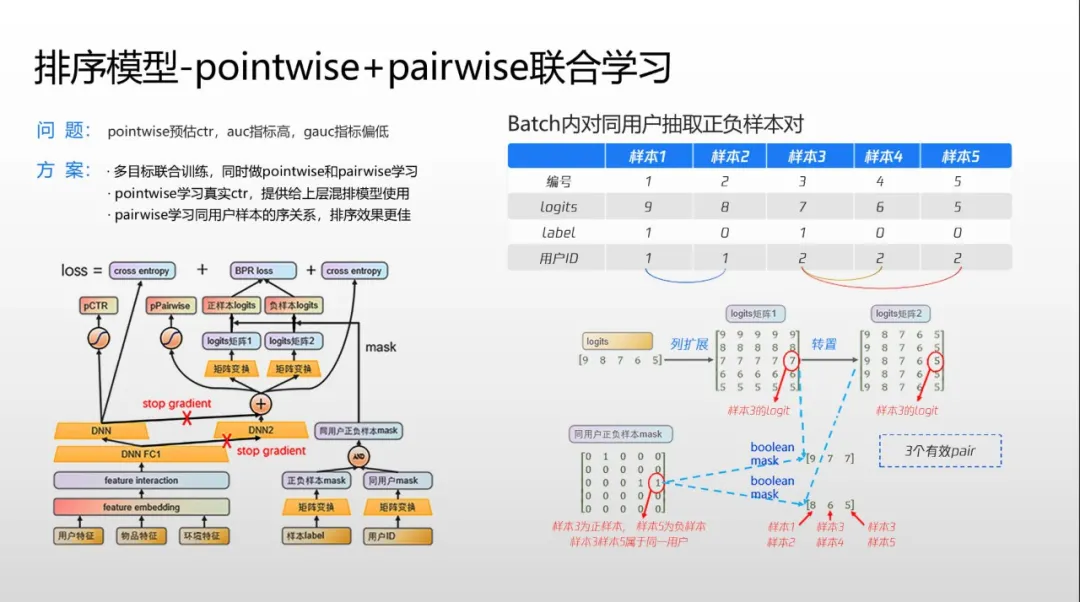
团队还打造了特色的 pointwise+pairwise 联合学习。其中 pointwise 一般用来预估 CPR 做 pCTR 输出,但用户序列学习效果不佳,所以往往 AUC 计算较好,但 GAUC 偏低。而 pairwise 的一般排序比 pointwise 更好,但前者无法生成 pCTR,亦即 CTR 用户值,但混排在上面的载控各层需要该值。如果 pointwise、pairwise 分别部署,两套模型需要两倍机器。为此团队提出改进,在输入时通过一些矩阵转制同时生成 pointwise 和 pairwise 样本,两者共享一些共同的输入特征、共享部分网络模型。上层 pointwise 和 pairwise 有各自独立的模型和计算,这样无需增加任何服务器成本就可以在一次样本流里同时输出两个结果,最后 pairwise 输出的 pCTR 用在其他场景,而 pairwise 排序结果作为精排结果输出。
多目标
在浏览器主 feeds 场景中,用户点击视频时,系统首先要预测各个视频点击率、卡片点击率;用户点击卡片进入视频沉浸流后,系统要预测第二层目标,预测各个视频完播率,预测用户是否会下滑,预估用户滑多少条视频、整体时长有多少;第三层目标还要预估用户在滑动过程中可能关注、收藏、分享哪些视频;第四层目标需要预估用户是否会观看视频评论或撰写评论。最终,系统会预估十多个目标,而多目标融合技术就负责将这些目标融合成合理的方式排序。
早期团队在做多目标融合的时候主要使用加法或者乘法结合超参数,核心是寻找最合理的超参数,现在则演进为用机器自动寻参。寻参方式从经典的网格计算演进到非个性化寻参,加入 BS 优化;最近模型演化到个性化寻参,每个用户都有自己独立的超参数。团队使用进化算法实现该体系,每次迭代后参数都会更靠近最优值。
调参结果会通过 AB 实验系统对接线上流量,每一次并行做几百上千组实验,以最快时间获得线上反馈,完成整体超参数优化。目前这套体系比之前的调参方法节约 50% 以上研发时间。
PCG 技术中台“无量”大规模分布式机器学习平台
QQ 浏览器平台使用的大规模分布式机器学习平台名为“无量”。由于 QQ 浏览器信息流每天曝光量达到百亿级,因而需要非常强大的计算平台。在这样的背景下诞生的腾讯 PCG 推荐中台超大规模深度学习系统—无量。无量平台能够训练百亿级样本,生成 TB 级别模型,在线上达到毫秒级推理。
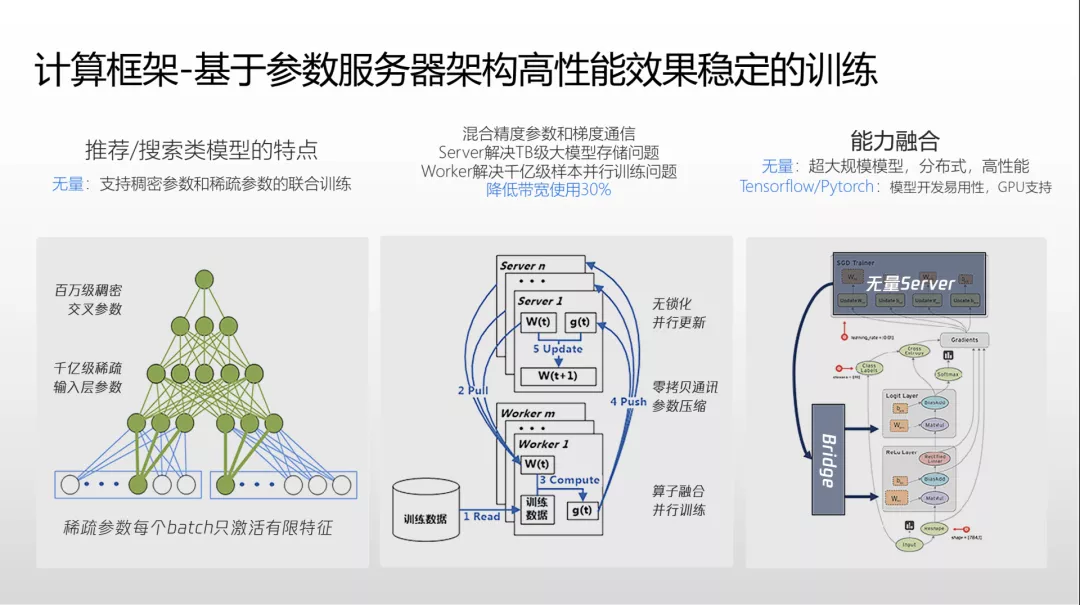
系统原有的模型迁移至无量后,各方面效果平均提升 20% 以上。无量采用参数服务器的设计理念,其针对平台的推荐、搜索算法特点,每一个 batch 只会激活较少的稀疏特征。底层可能是稀疏参数,规模千亿级,上层可能是百万级较稠密的参数。
无量是 worker 和 server 分布式架构,其中 server 负责 TB 级模型的存储更新和推理,worker 负责百亿级样本的分布式训练。分布式计算涉及巨量网络通讯,所以无量引入了零字节网络通讯拷贝、混合精度压缩等技术,降低 worker 和 server 之间的网络通信量。
无量平台不仅能支持腾讯自研模型,还支持 TensorFlow、PyTorch 等众多第三方框架,方便现有模型代码迁移。
无量平台在推理方面遇到很多挑战,其中每次请求需要访问多达十几万次 key 的数量级,系统峰值达到几十亿次 QPS 访问量。传统系统的读写锁、主备设计无法满足如此高的性能要求,因此腾讯自研了一套基于内存的模型存储系统,实现多线程无锁、单个模型定型读取、主副版本读写分离等,满足了超高规格的性能需求。
针对大规模模型的线上更新挑战,团队采用了 TB 级大模型全量更新每 4 到 8 小时一次,增量模型 10 分钟一次,实模型和 KB 级模型毫秒级更新的策略。
团队还将推荐模型的训练和推理工作都迁移到了 GPU 上。为了解决 GPU 显存较小的挑战,团队应用了大量优化。训练阶段需要非常高的吞吐量,所以团队将每一次训练样本中需要用到的高频参数样本放入 GPU 显存,下一次可能使用的参数特征放入 CPU 内存,其他参数放入 SSD。推理阶段需要更低的延时和更高的并发,因此团队对线上千亿级特征实时统计访问频率,将高频参数放入推理的 GPU 显存,中频参数放入内存,低频参数放入分布式内存 serving 集群。
线上推理迁移到 GPU 后节省了一半成本,改进非常显著。
NLP、CV 与视频理解
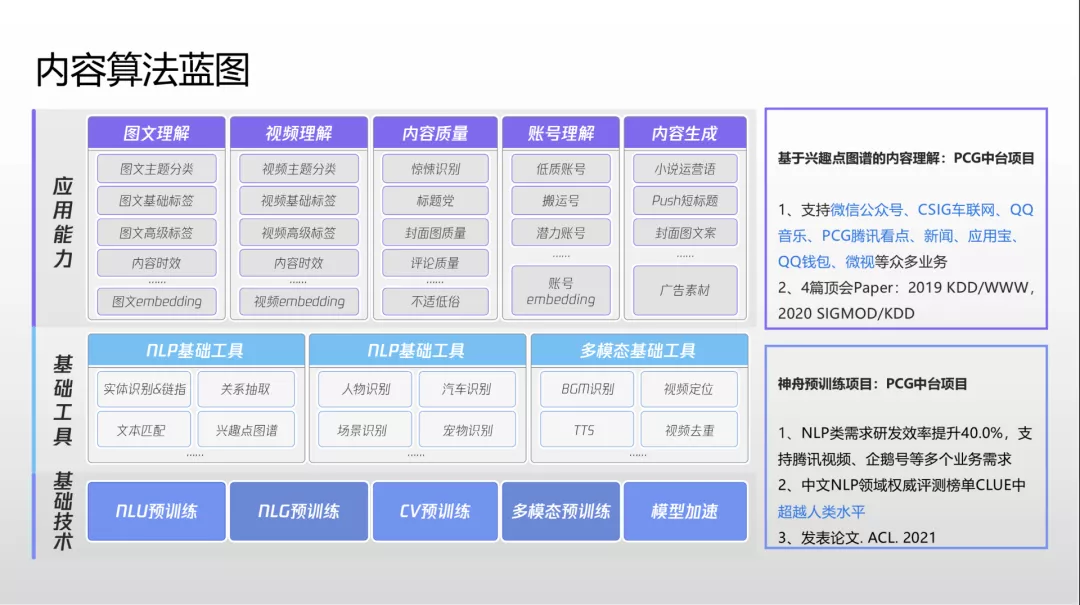
兴趣点图谱
在 QQ 浏览器内容算法中,兴趣点图谱的本质是打标签。团队面临的挑战是如何将标签打全,打准,打出标签与标签之间的组合关系,打出一些概念标签,像人类一样打出感情的标签,等等。
2019 年,团队主要聚焦语义领域,解决概念标签问题。例如一篇手机评测文章没有直接列举手机价格、描述拍照好坏,而系统可以通过概念抽象提炼文章标签,总结出“这是高性价比拍照功能特别好的手机”这样的主题。
2020 年,团队主要开发聚集话题、事件的关联能力。例如系统通过话题聚合和事件生成能力把和东京奥运相关的成千上万视频文章,聚合到事件脉络和每个话题中,形成事件和话题的图谱体系。
今年团队聚焦小视频标签领域,希望解决更深层次的语义提炼问题,希望 NLP 像人类一样打情感类标签。
此外,系统现在可以基于用户喜欢的明星做推荐,或者通过“高颜值”这样的概念标签进行推荐。现在平台的兴趣点图谱有接近 100 万个兴趣点,全面覆盖所有中文内容几乎每一个垂直领域。
神舟预训练模型
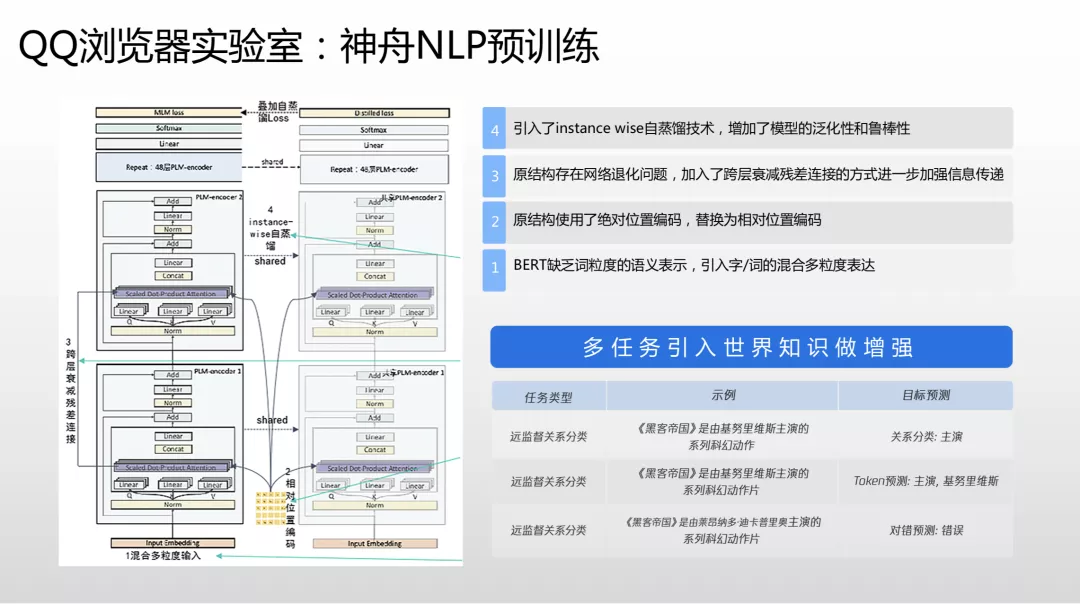
QQ 浏览器团队在两个月前推出了神舟预训练模型,不仅在权威的中文语言理解测评基准拿到冠军,还在二十多个分类和语义标签任务上第一次超过了人类专家标注的水平,是比较有标志性意义的技术。
预训练的业务在推荐技术,搜索业务里都有大规模使用。之前的 BERT 主要优化英文,对汉语支持不佳,所以团队做了字词混合力度表达输入到特征里;BERT 使用了绝对未知编码,而团队发现汉语里用相对未知编码效果更好,能让语义相关的 Embedding 离得更近,而不相似语义的 Embedding 离得更远;针对 BERT 的网络退化问题,团队做了跨层衰减的残差连接,以优化整个网络的信息传递;同时团队还做了模型蒸馏技术,做了数据增强,引入世界知识。QQ 浏览器内部有知识图谱团队,有百万千万级经过人工专家标注过的优质准确世界知识数据,因此把它引入到预训练里做增强有明显效果。
在实践中,团队将所有的 NLP 任务都使用神舟做预训练,结合微调和一些混合粒度优化,结果使下游每任务的语料标注数量减少 40% 以上。同时团队研发了一套专门基于预训练加 fintune 的流程,让整个 NLP 的研发周期减少 40%。
视频多模型预训练
做完 NLP 预训练,下一步要做视频多模型预训练。首先要做抽真,抽真以后基于图像级别预训练,生成视觉方面的预训练模型。神舟已经生成了视频标题、简介、字幕、各种语音 OCR 的预训练模型,再加上视频里一些语音或音乐等信息,实现了视觉、图文、听觉方面的语义对齐,最后生成多模态预训练模型。
上述所有能力的底层现在都换成了多模态预训练框架,效果和效率都有较大提升。多模态预训练还可用在图文和视频的联合 Embedding 检索方面。图文正文底部要做一些视频相关推荐,系统可以用文章生成的向量和视频的多模态向量做关联召回检索,显著提升图文视频的用户渗透率。
PCG AI 与推荐中台
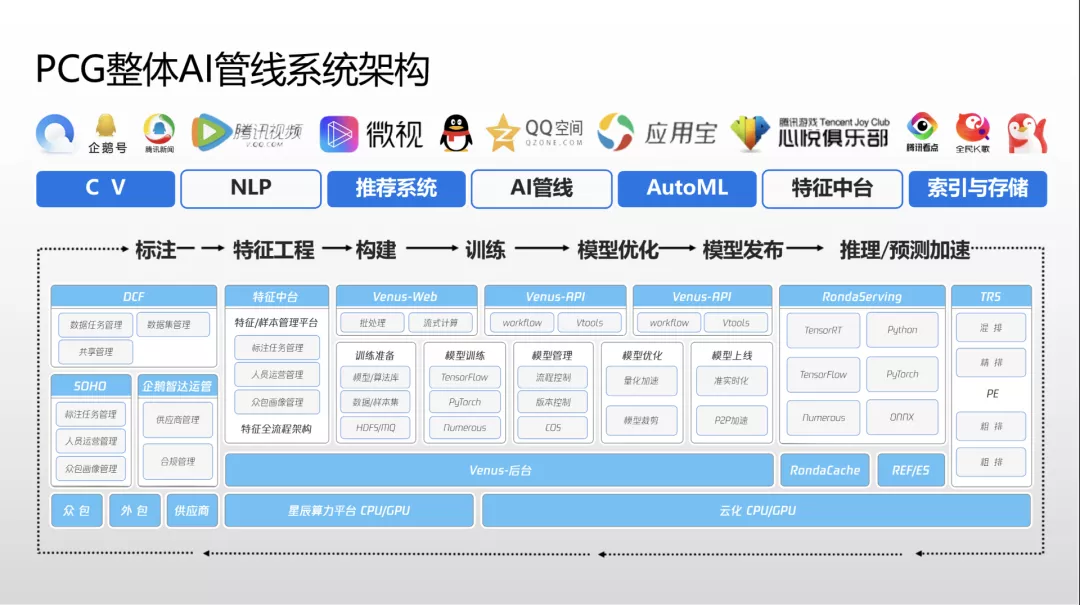
PCG 的 AI 中台是腾讯官方比较大的中台项目。AI 中台包括七个方向,本次分享主�
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E8%85%BE%E8%AE%AF%E6%8A%80%E6%9C%AF%E4%B8%8E%E6%8E%A8%E8%8D%90%E6%8A%80%E6%9C%AF%E5%9C%A8%E8%85%BE%E8%AE%AF%E6%B5%8F%E8%A7%88%E5%99%A8%E7%9A%84%E5%BA%94%E7%94%A8/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


