腾讯技术揭秘信息流推荐背后的系统设计
作者:徐宁,腾讯应用开发工程师,腾讯学院讲师
导语 | 本文将总结一下常用的基于时间线Feed流的后台存储设计方案。结合具体的业务场景,讲述一下根据实际需求,在基本设计思路上做一些灵活运用。
一、背景
Feed流产品在我们手机APP中几乎无处不在,常见的Feed流比如微信朋友圈、新浪微博、今日头条等。对Feed流的定义,可以简单理解为只要大拇指不停地往下划手机屏幕,就有一条条的信息不断涌现出来。就像给牲畜喂饲料一样,只要它吃光了就要不断再往里加,故此得名Feed(饲养)。
大多数Feed流产品都包含两种Feed流,一种是基于算法推荐,另一种是基于关注(好友关系)。例如下图中的微博和知乎,顶栏的页卡都包含“关注”和“推荐”这两种。两种Feed流背后用到的技术差别会比较大。本文将重点探索一下“关注”页卡的后台实现方式。
不同于“推荐”页卡那种千人千面算法推荐的方式,通常“关注”页卡所展示的内容先后顺序都有固定的规则,最常见的规则是基于时间线来排序,也就是展示“ 我关注的人所发的帖子,根据发帖时间从晚到早依次排列”。
二、Feed流实现方案介绍
方案1——读扩散
读扩散也称为“拉模式”,这应该是最符合我们直觉的一种实现方式。如下图:
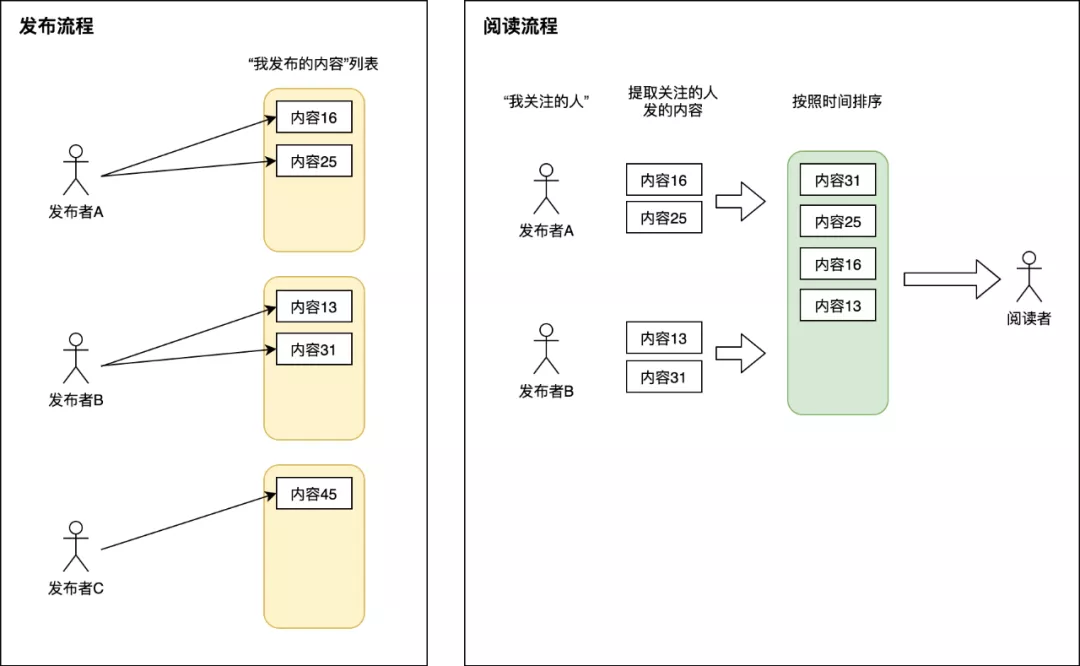
每一个内容发布者都有一个自己的发件箱(“我发布的内容”),每当我们发出一个新帖子,都存入自己的发件箱中。当我们的粉丝来阅读时,系统首先需要拿到粉丝关注的所有人,然后遍历所有发布者的发件箱,取出他们所发布的帖子,然后依据发布时间排序,展示给阅读者。
这种设计, 阅读者读一次Feed流,后台会扩散为N次读操作(N等于关注的人数)以及一次聚合操作,因此称为读扩散。每次读Feed流相当于去关注者的收件箱主动拉取帖子,因此也得名——拉模式。
这种模式的好处是底层存储简单,没有空间浪费。坏处是每次读操作会非常重,操作非常多。设想一下如果我关注的人数非常多,遍历一遍我所关注的所有人,并且再聚合一下,这个系统开销会非常大,时延上可能达到无法忍受的地步。因此读扩散主要适用系统中阅读者关注的人没那么多,并且刷Feed流并不频繁的场景。
拉模式还有一个比较大的缺点就是分页不方便,我们刷微博或朋友圈,肯定是随着大拇指在屏幕不断划动,内容一页一页的从后台拉取。如果不做其他优化,只采用实时聚合的方式,下滑到比较靠后的页码时会非常麻烦。
方案2——写扩散
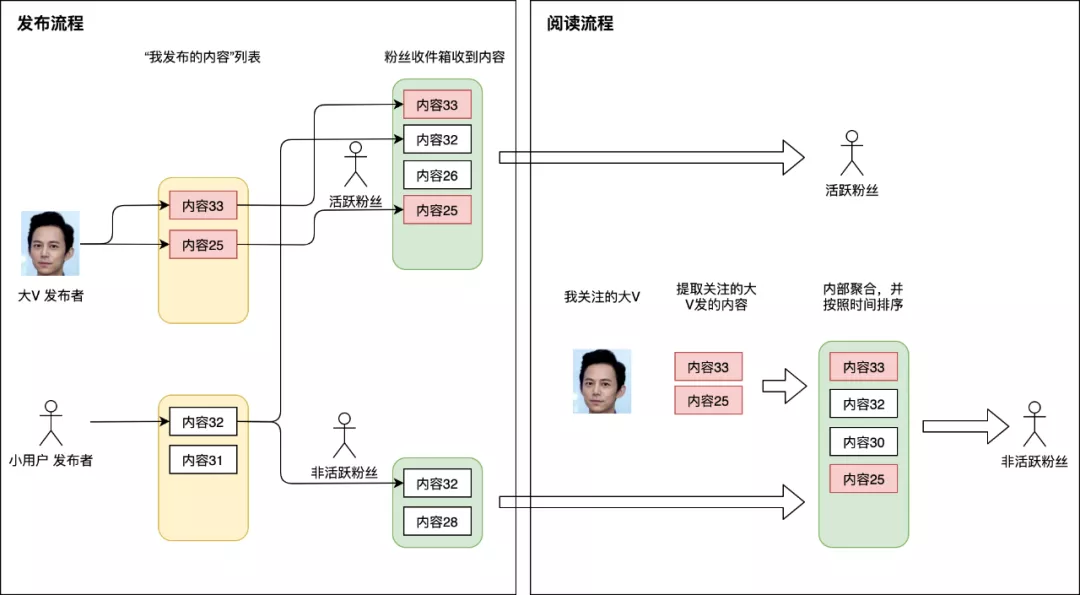
据统计,大多数Feed流产品的读写比大概在100:1,也就是说大部分情况都是刷Feed流看别人发的朋友圈和微博,只有很少情况是自己亲自发一条朋友圈或微博给别人看。因此,读扩散那种很重的读逻辑并不适合大多数场景。我们宁愿让发帖的过程复杂一些,也不愿影响用户读Feed流的体验,因此稍微改造一下前面方案就有了写扩散。写扩散也称为“推模式”,这种模式会对拉模式的一些缺点做改进。如下图:
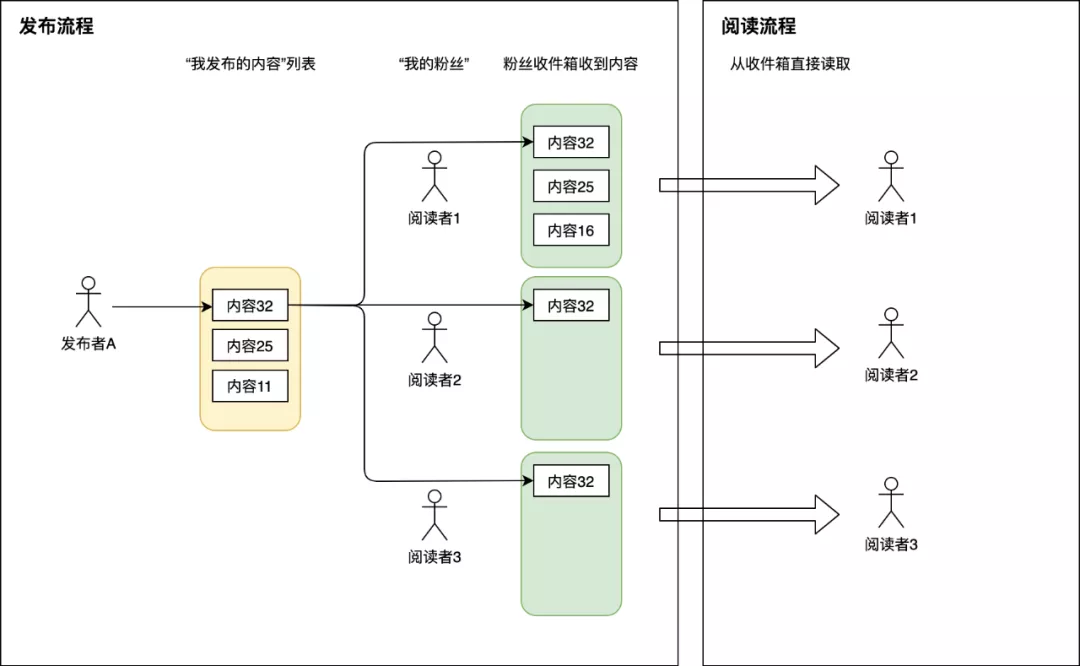
系统中每个用户除了有发件箱,也会有自己的收件箱。当发布者发表一篇帖子的时候,除了往自己发件箱记录一下之外,还会遍历发布者的所有粉丝,往这些粉丝的收件箱也投放一份相同内容。这样阅读者来读Feed流时,直接从自己的收件箱读取即可。
这种设计, 每次发表帖子,都会扩散为M次写操作(M等于自己的粉丝数),因此成为写扩散。每篇帖子都会主动推送到所有粉丝的收件箱,因此也得名推模式。
这种模式可想而知,发一篇帖子,背后会涉及到很多次的写操作。通常为了发帖人的用户体验,当发布的帖子写到自己发件箱时,就可以返回发布成功。后台另外起一个异步任务,不慌不忙地往粉丝收件箱投递帖子即可。写扩散的好处在于通过数据冗余(一篇帖子会被存储M份副本),提升了阅读者的用户体验。通常适当的数据冗余不是什么问题,但是到了微博明星这里,完全行不通。比如目前微博粉丝量Top2的谢娜与何炅,两个人微博粉丝过亿。
设想一下,如果单纯采用推模式,那每次谢娜何炅发一条微博,微博后台都要地震一次。一篇微博导致后台上亿次写操作,这显然是不可行的。另外由于写扩散是异步操作,写的太慢会导致帖子发出去半天,有些粉丝依然没能看见,这种体验也不太好。
通常 写扩散适用于好友量不大的情况,据悉微信朋友圈正是写扩散模式。每一名微信用户的好友上限为5000人,也就是说你发一条朋友圈最多也就扩散到5000次写操作,如果异步任务性能好一些,完全没有问题。
方案3——读写混合模式
读写混合也可以称作“推拉结合”。这种方式可以兼具读扩散和写扩散的优点。我们首先来总结一下读扩散和写扩散的优缺点:
方案优点缺点适用场景读扩散节约存储空间,发帖操作简单读帖操作复杂,关注人数多时是灾难用户不活跃,很少读帖;有大V粉丝量多,但每个粉丝关注的人少写扩散读帖操作简单发帖操作复杂,浪费存储空间;大V粉丝量多时是灾难用户非常活跃,经常刷帖;无大V,用户粉丝量都比较少
仔细比较一下读扩散与写扩散的优缺点,不难发现两者的适用场景是互补的。因此在设计后台存储的时候,我们如果能够区分一下场景,在不同场景下选择最适合的方案,并且动态调整策略,就实现了读写混合模式。如下图:
当何炅这种粉丝量超大的人发帖时,将帖子写入何炅的发件箱,另外提取出来何炅粉丝当中比较活跃的那一批(这已经可以筛掉大部分了),将何炅的帖子写入他们的收件箱。当一个粉丝量很小的路人甲发帖时,采用写扩散方式,遍历他的所有粉丝并将帖子写入粉丝收件箱。
对于那些活跃用户登录刷Feed流时,他直接从自己的收件箱读取帖子即可,保证了活跃用户的体验。当一个非活跃的用户突然登录刷Feed流时,我们一方面需要读他的收件箱,另一方面需要遍历他所关注的大V用户的发件箱提取帖子,并且做一下聚合展示。在展示完后,系统还需要有个任务来判断是否有必要将该用户升级为活跃用户。因为有读扩散的场景存在,因此即使是混合模式,每个阅读者所能关注的人数也要设置上限,例如新浪微博限制每个账号最多可以关注2000人。如果不设上限,设想一下有一位用户把微博所有账号全部关注了,那他打开关注列表会读取到微博全站所有帖子,一旦出现读扩散,系统必然崩溃;即使是写扩散,他的收件箱也无法容纳这么多的微博。
读写混合模式下,系统需要做两个判断。一个是哪些用户属于大V,我们可以将粉丝量作为一个判断指标。另一个是哪些用户属于活跃粉丝,这个判断标准可以是最近一次登录时间等。这两处判断标准就需要在系统发展过程中动态地识别和调整,没有固定公式了。
可以看出读写结合模式综合了两种模式的优点,属于最佳方案。然而他的缺点是系统机制非常复杂,给程序员带来无数烦恼。通常在项目初期,只有一两个开发人员,用户规模也很小的时候,一步到位地采用这种混合模式还是要慎重,容易出bug。当项目规模逐渐发展到新浪微博的水平,有一个大团队专门来做Feed流时,读写混合模式才是必须的。
Feed流中的分页问题
前文已经叙述了基于时间线的Feed流常见设计方案,但实操起来会比理论要麻烦许多。接下来专门讨论一个困难点——Feed流的分页。不管是读扩散还是写扩散,Feed流本质上是一个动态列表,列表内容会随着时间不断变化。传统的前端分页参数使用page_size和page_num,分表表示每页几条,以及当前是第几页。对于一个动态列表会有如下问题:
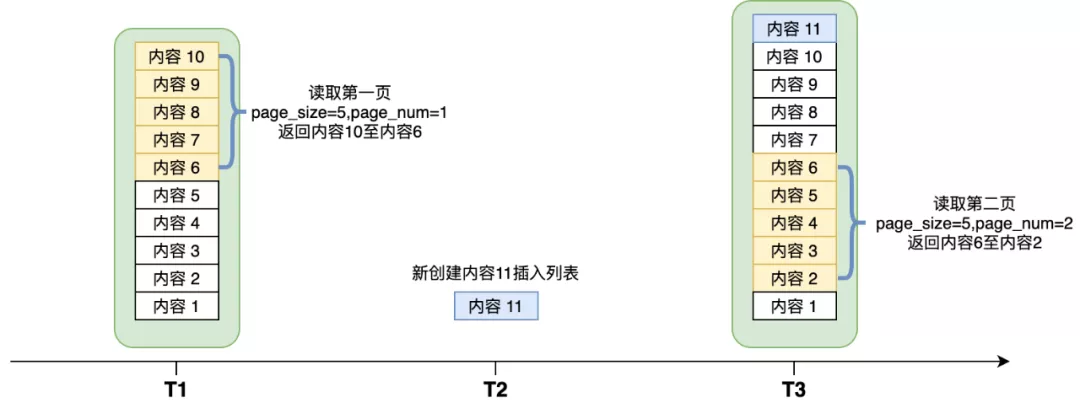
在T1时刻读取了第一页,T2时刻有人新发表了“内容11”,在T3时刻如果来拉取第二页,会导致错位出现,“内容6”在第一页和第二页都被返回了。事实上,但凡两页之间出现内容的添加或删除,都会导致错位问题。
为了解决这一问题,通常Feed流的分页入参不会使用page_size和page_num,而是使用last_id来记录上一页最后一条内容的id。前端读取下一页的时候,必须将last_id作为入参,后台直接找到last_id对应数据,再往后偏移page_size条数据,返回给前端,这样就避免了错位问题。如下图:
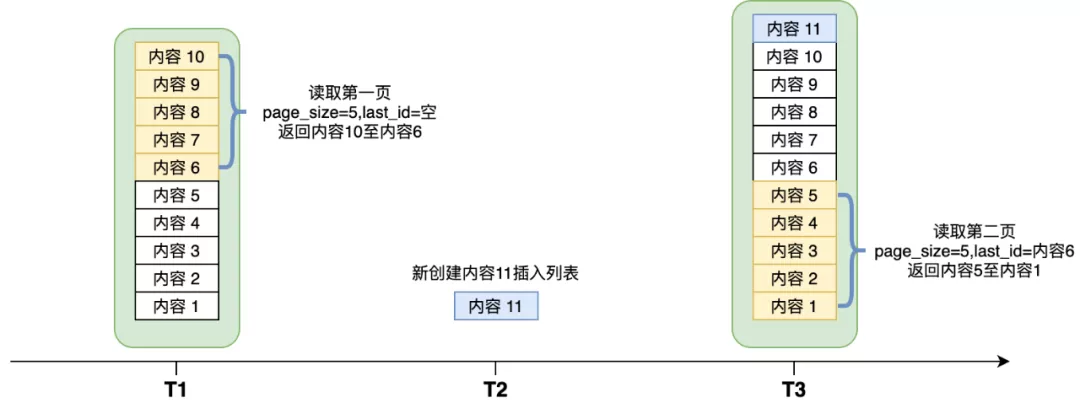
采用last_id的方案有一个重要条件,就是last_id本身这条数据不可以被硬删除。设想一下上图中T1时刻返回5条数据,last_id为内容6;T2时刻内容6被发布者删除;那么T3时刻再来请求第二页,我们根本找不到last_id对应的数据了,也就无法确认分页偏移量。通常碰到删除的场景,我们采用软删除方式,只是在内容上置一个标志位,表示内容已删除。由于已经删除的内容不应该再返回给前端,因此软删除模式下,找到last_id并往后偏移page_size条,如果其中有被删除的数据会导致获得足够的数据条数给前端。这里一个解决方案是找不够继续再往下找,另一种方案是与前端协商,允许返回条数少于page_size条,page_size只是个建议值。甚至大家约定好了以后,可以不要page_size参数。
三、实际业务应用
(一)业务需求
文章最后结合我们自身业务,介绍一下实际业务场景中碰到的一个非常特殊的Feed流设计方案。直享直播是一款直播带货工具,主播可以创建一场未来时刻的直播,到时间后开播卖货,直播结束后,主播的粉丝可以查看直播回放。这样,每个直播场次就有三种状态——预告中(创建一场直播但还未开播)、直播中、回放。作为观众,我可以关注多位主播,这样从粉丝视角来看,也会有个直播场次的Feed流页面。这个Feed流最特殊的地方在于它的Feed流排序规则。
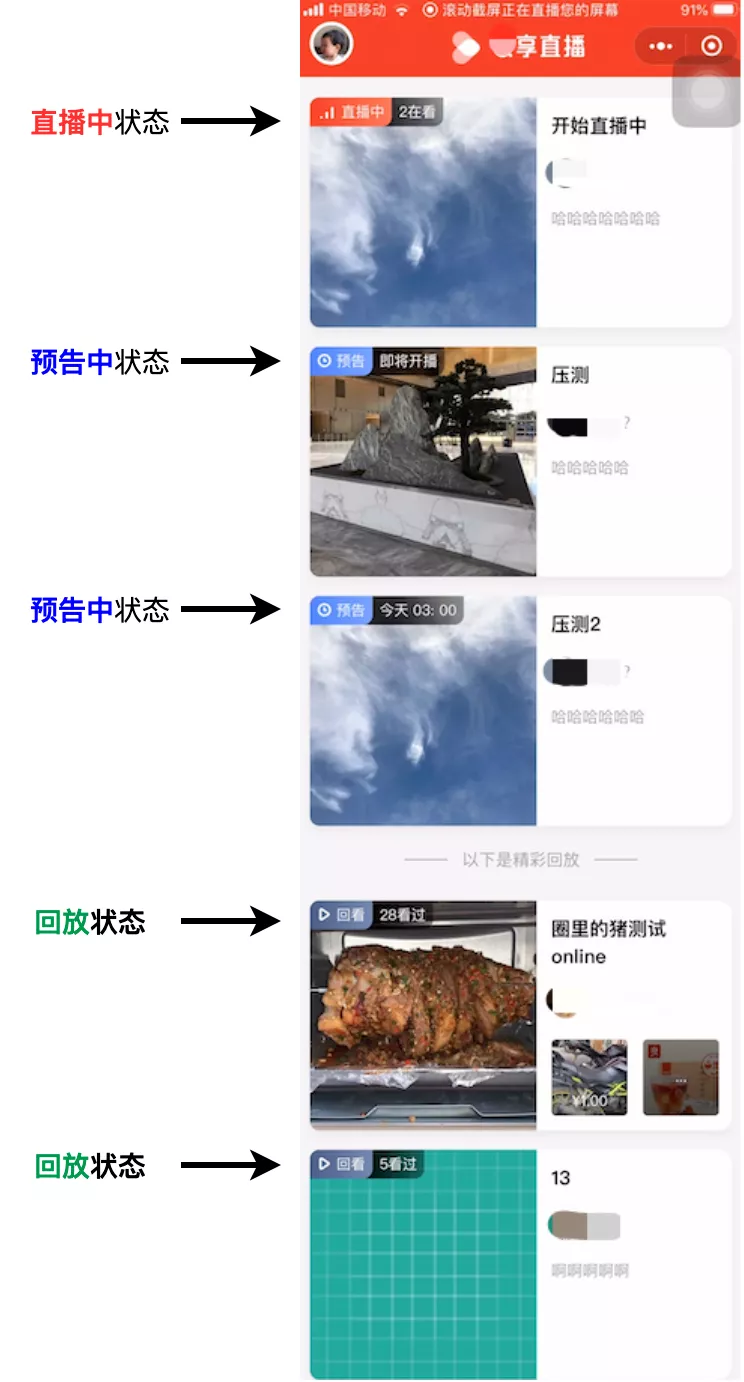
Feed流排序规则:
1.我关注的所有主播, 正在直播中的场次排在最前;预告中的场次排中间;回放场次排最后;
2.多场次都在直播中的, 按开播时间从晚到早排序;
3.多场次都在预告中的, 按预计开播时间从早到晚排序;
4.多场次都在回放的, 按直播结束时间从晚到早排序。
(二)问题分析
本需求最复杂的点在于Feed流内容融入的“状态”因素,状态的转变会直接导致Feed流顺序不同。为了更清晰解释一下对排序的影响,我们可以用下图详细说明:
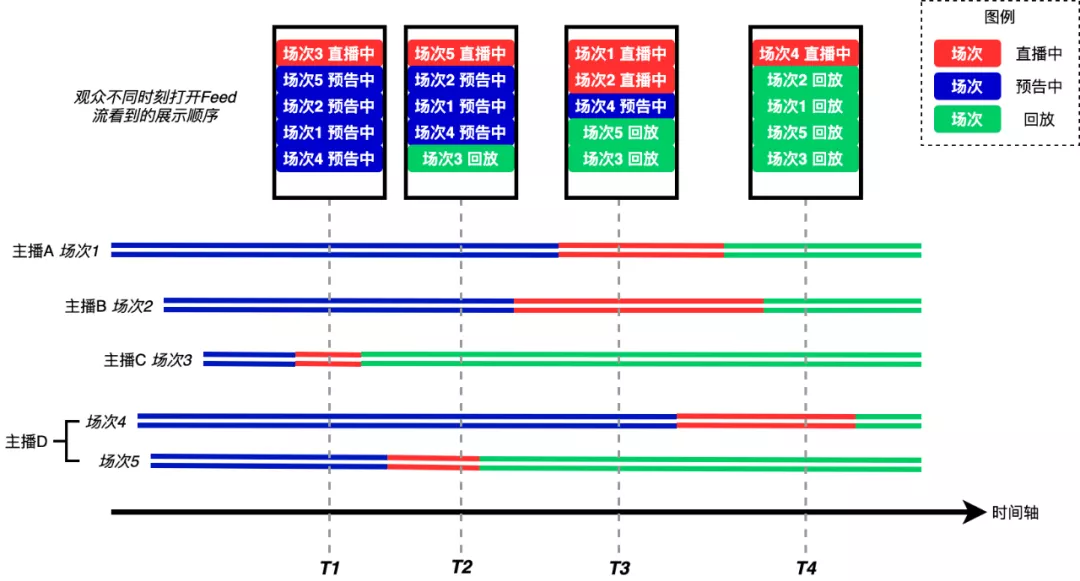
图中展示了4个主播的5个直播场次,作为观众,当我在T1时刻打开页面,看到的顺序是场次3在最上方,其余场次均在预告状态,按照预计开播时间从早到晚展示。当我在T2时刻打开页面,场次5在最上方,其余有三场在预告状态排在中间,场次3已经结束了所以排在最后。以此类推,直到所有直播都结束,所有场次最终的状态都会变为回放。
这里需要注意一点,如果我在T1时刻打开第一页,然后盯着页面不动,一直盯到T4时刻再下划到第二页,这时上一页的last_id,即分页偏移量很有可能因为直播状态变化而不知道飞到了什么位置,这会 导致严重的错位问题,以及直播状态展示不统一的问题(第一页展示的是T1时刻的直播状态,第二页展示的是T4时刻的直播状态)。
(三)解决方案
直播系统是个单向关系链,和微博有些类似, 每个观众会关注少量主播,每个主播会可能有非常多的关注者。由于有状态变化的存在,写扩散几乎无法实现。因为如果采用写扩散的方式,每次主播创建直播、直播开播、直播结束这三个事件发生时导致的场次状态变化,会扩散为非常多次的写操作,不仅操作复杂,时延上也无法接受。微博之所以可以写扩散,就是因为一篇帖子发出后,这篇帖子就不会再有任何影响排序的状态转变。在我们场景中,“预告中”与“直播中”是两个中间态,而“回放”状态才是所有直播的最终归宿,一旦进入回放,这场直播也就不会再有状态转变。因此**“直播中”与“预告中”状态可以采用读扩散方式,“回放”状态采取写扩散方式**。
最终的方案如下图所示:
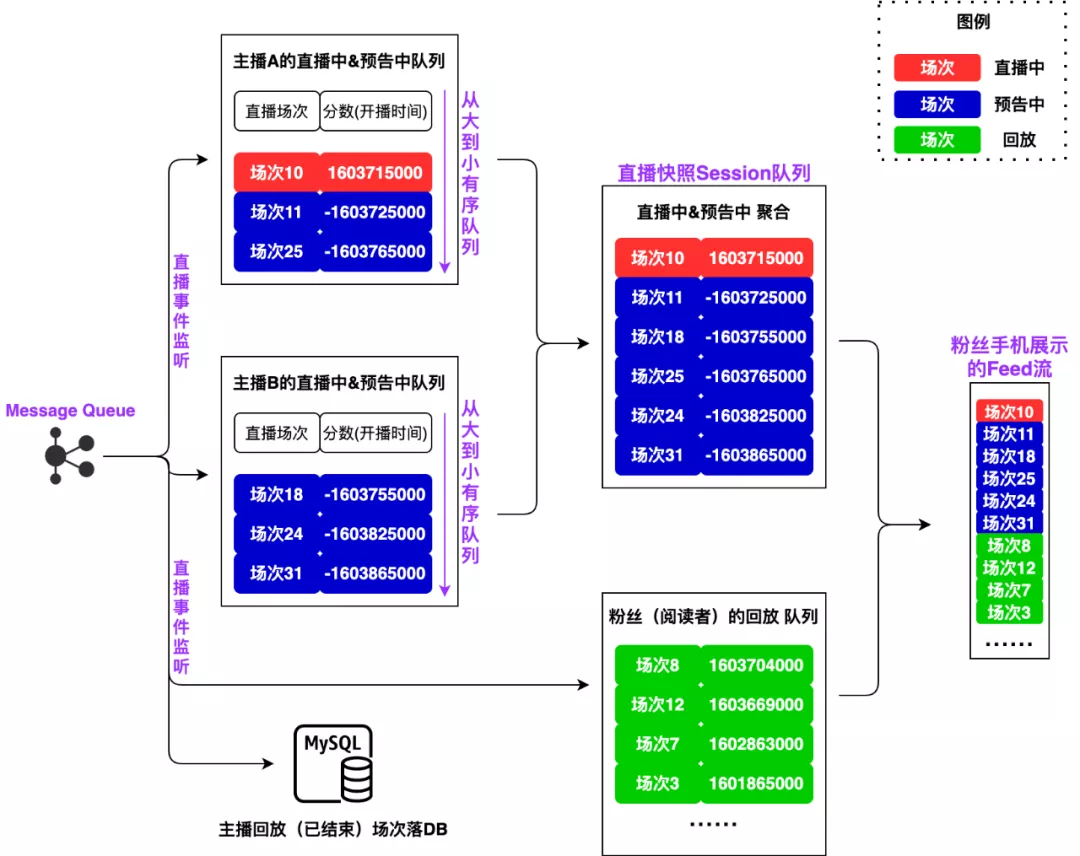
会影响直播状态的三种事件(创建直播、开播、结束直播)全部采用监听队列异步处理。我们为每一位主播维护一个直播中+预告中状态的优先级队列。每当监听到有主播创建直播时,将直播场次加入队列中,得分为开播的时间戳的相反数(负数)。每当监听到有主播开播时,把这场直播在队列中的得分修改为开播时间(正数)。每当监听到有主播结束直播,则异步地将播放信息投递到每个观众的回放队列中。
这里有一个小技巧,前文提到,直播中状态按照开播时间从大到小排序,而预告中状态则按照开播时间从小到大排序,因此如果将预告中状态的得分全部取开播时间相反数,那排序同样就成为了从大到小。这样的转化可以保证直播中与预告中同处于一个队列排序。 预告中得分全都为负数,直播中得分全都为正数,最后聚合时可以保证所有直播中全都自然排在预告中前面。
另外前文还提到的另一个问题是T1时刻拉取第一页,T4时刻拉取第二页,导致第一页和第二页直播间状态不统一。解决这个问题的办法是通过快照方式。当观众来拉取第一页Feed流时,我们依据当前时间,将全部直播中和预告中状态的场次建立一份快照,使用一个session_id标识,每次前端分页拉取时,我们直接从快照中读取即可。如果快照中读取完毕,证明该观众的直播中和预告中场次全部读完,剩下的则使用回放队列进行补充。照此一来,我们的Feed流系统,前端分页拉取的参数一共有4个:
含义值来源读第一页时参考值session_id
快照队列ID,从该快照中读取直播中和预告中场次上一页返回值
空字符串
last_id
上一页读取到哪一场直播上一页返回值空字符串state
枚举值0或1,表示last_id处于快照队列还是回放队列上一页返回值0
page_size
每页建议读几条前后端约定10
每当碰到session_id和last_
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E8%85%BE%E8%AE%AF%E6%8A%80%E6%9C%AF%E6%8F%AD%E7%A7%98%E4%BF%A1%E6%81%AF%E6%B5%81%E6%8E%A8%E8%8D%90%E8%83%8C%E5%90%8E%E7%9A%84%E7%B3%BB%E7%BB%9F%E8%AE%BE%E8%AE%A1/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


