行知镶嵌在互联网技术上的明珠漫谈深度学习时代点击率预估技术进展

文章作者: 朱小强****(阿里花名: 怀人)**** 阿里妈妈深度学习算法平台负责人,兼任定向广告&信息流广告排序技术团队负责人
内容来源: 高维稀疏数据领域的深度学习****@知乎专栏****
出品社区: DataFun
注:欢迎投稿「行知」,投递方式见文末。
一、写在前面
关于标题所承载的话题,一直有计划写个总结,没料到各种耽搁,从17年底拖到了19年的今天。不过这也带来了一点额外的收获,18年呈现的新挑战让我对技术的发展脉络和关键点有了更深刻的认知。因此在这个时间点,在深度学习(Deep Learning,下文简称DL)落地互联网、驱动业界技术的轮子旋转了差不多第一圈的时候,系统地把我们的实践经验做个梳理和盘点,跟大伙聊聊,对业界、对不少还在这条路上折腾的同行们,权当一个可做粗浅参考的路标。此外,既然踩在了第二圈即将转动的交叉点附近,也斗胆对下一阶段技术的发展抛些板砖,谈谈我们看到的挑战和趋势。
能力有限, 本文主要以点击率(Click-Through Rate, CTR)预估技术这个战场来展开叙述: 1) 这是我熟悉的主场,下文叙述也主要以我负责的阿里定向广告点击率预估技术发展过程为蓝本; 2) 我常把CTR预估技术类比为数学领域的黎曼猜想,它是镶嵌在互联网应用技术上的一颗闪亮的明珠,它的技术前进既是业界技术的真实写照、很多时候也是引领和驱动互联网应用技术发展的原力(广告领域的性价比因素)。当然资深的从业者们应该都清楚,互联网一大批核心技术都跟CTR预估有着千丝万缕的联系,因此这里技术的探讨足够典型。
为了不引起误解,提前交代一下,本文主要是基于我们团队公开发表的论文,探讨技术为主,不宜披露的数字都隐去了。这些技术绝大部分都已经在实际生产系统中落地、服务着阿里典型业务(如定向广告、信息流广告等)的主流量,且取得了显著的收益。一个可以公开的数字是,基于DL的CTR技术迭代已经带来了超过百亿人民币规模的直接广告收入增长。目前在国内,阿里妈妈的广告市场份额是无可争议的第一。因此读者可以放心,这些技术不是华而不实的炫技,而是真正经受过工业级规模洗礼的实战利器。此外,本文不是详细地给大家解读paper,而是跳出结果、回归技术思考,探讨DL驱动这个领域技术发展的过往、现在和未来。
倡导:技术的封闭性在open-source时代已经不堪一击。业界顶尖团队的领先优势最多保持半年到一年,拥抱开放、共同推进行业技术的发展是不可阻挡的洪流,也是我们行为背后的驱动力。
二、深度学习驱动的CTR预估技术演化
0. 浅层模型时代:以MLR为例
2005-2015这十年间,大规模机器学习模型(特指浅层模型)一度统治着CTR预估领域,以G/B两家为代表的”大规模离散特征+特征工程+分布式线性LR模型”解法几乎成为了那个时代的标准解。相关的工作相信读者们耳熟能详,甚至据我所知今天业界的不少团队依然采用这样的技术。
阿里在2011-2012年左右由@盖坤同学创新性地提出了MLR(Mixed Logistic Regression)模型并实际部署到线上系统,同时期也有如FM模型等工作出现。这些模型试图打破线性LR模型的局限性,向非线性方向推进了一大步。
我在2014年加入阿里定向广告团队,不久负责了Ranking方向,推进CTR技术的持续迭代是我工作的主航道之一。作为MLR模型的诞生团队,显然我们对它有着强烈的偏爱。最初MLR模型的主要使用方式是”低维统计反馈特征+MLR”,这是受阿里技术发展初期的轨道限制,读者不用太惊讶。我们做的第一个工作,就是试图将MLR模型推向大规模离散特征体系,核心思考是细粒度的特征刻画携带的信息量要远比统计平均特征的分辨率高,这种特征体系至今在整个业界都是最先进的。要完成这样一个升级,背后有巨大的挑战(在DL时代启动初期,我们也遇到了类似的挑战),具体包括:
-
从数百维统计特征到数十亿离散特征,训练程序要做重大升级,从数据并行模式要升级到模型并行方式,且非线性模型复杂度高,需要充分利用数据的结构化特点进行加速;
-
”大规模离散特征+分布式非线性MLR模型”解法直接从原始离散特征端到端地进行数据模式学习,至少在初期时我们没有做任何的特征组合,完全依赖模型的非线性能力。在这种互联网尺度(百亿参数&样本)的数据上,模型能不能学习到兼具拟合能力与泛化能力的范式?
-
这种超大规模数据上的非凸优化(MLR加入正则后进一步变成非光滑)学术界鲜有先例。它的收敛性是一个巨大的问号。
当然,结果是我们成功了。15年初的时候成为了新的技术架构,在定向广告的所有场景都生产化落地,取得了巨大的成功。但是我们不得不承认,”大规模离散特征+分布式非线性MLR模型”的解法在业界并没有大规模地被采纳,有多种原因,技术上来讲MLR模型的实现细节我们直到17年才正式地写了一篇论文挂在了arxiv上,代码也没有开源,大家想要快速尝试MLR也不太方便;其次LR+特征工程的解法深深影响了很多技术团队的思考方式和组织结构,我们后面会谈到,这种对特征工程的依赖直到DL时代还大量保留着,一个重要的因素也是因为特征工程比较符合人的直观认知,可以靠快速试错并行迭代,MLR这类非线性端到端的解法需要比较强的模型信仰和建模能力。
大约从14年到16年,我们在基础MLR架构上做了大量的优化,后来以MLR的论文公布为契机,我在阿里技术官微里面写了一篇介绍文章,里面披露了大量的改进细节,大家有兴趣可以翻阅翻阅,算是致敬MLR时代: MLR深度优化细节
1. 技术拐点:端到端深度学习网络的突破
15年的时候,基于MLR的算法迭代进入瓶颈。当时认识到,要想进一步发挥MLR模型的非线性能力,需要提高模型的分片数——模型的参数相应地会线性增长,需要的训练样本量同样要大幅度增加,这不太现实。期间我们做了些妥协,从特征的角度进行优化,比如设计了一些直观的复合特征,典型的如”hit类特征”:用户历史浏览过商品A/B/C,要预估的广告是商品C,通过集合的”与”操作获得”用户历史上浏览过广告商品”这个特征。细心的读者应该很容易联想到后来我们进一步发展出来的DIN模型,通过类似attention的技巧拓展了这一方法。后来进一步引入一些高阶泛化特征,如user-item的PLSA分解向量、w2v embedding等。但这些特征引入的代价大、收益低、工程架构复杂。
15年底16年初的时候我们开始认真地思考突破MLR算法架构的限制,向DL方向迈进。这个时间在业界不算最早的,原因如前所述,MLR是DL之前我们对大规模非线性建模思路的一个可行解,它助力了业务巨大的腾飞,因此当时够用了——能解决实际问题就是好武器,这很重要。在那个时间点,业界已经有了一些零散的DL建模思路出现,最典型的是B家早期的两阶段建模解法——先用LR/FM等把高维离散特征投影为数千规模的稠密向量,然后再训练一个MLP模型。我们最初也做过类似的尝试如w2v+MLR/DNN,但是效果不太显著,看不到打败MLR的希望(不少团队从LR发展过来,这种两阶段建模打败LR应该是可行的)。这里面关键点我们认为是端到端的建模范式。
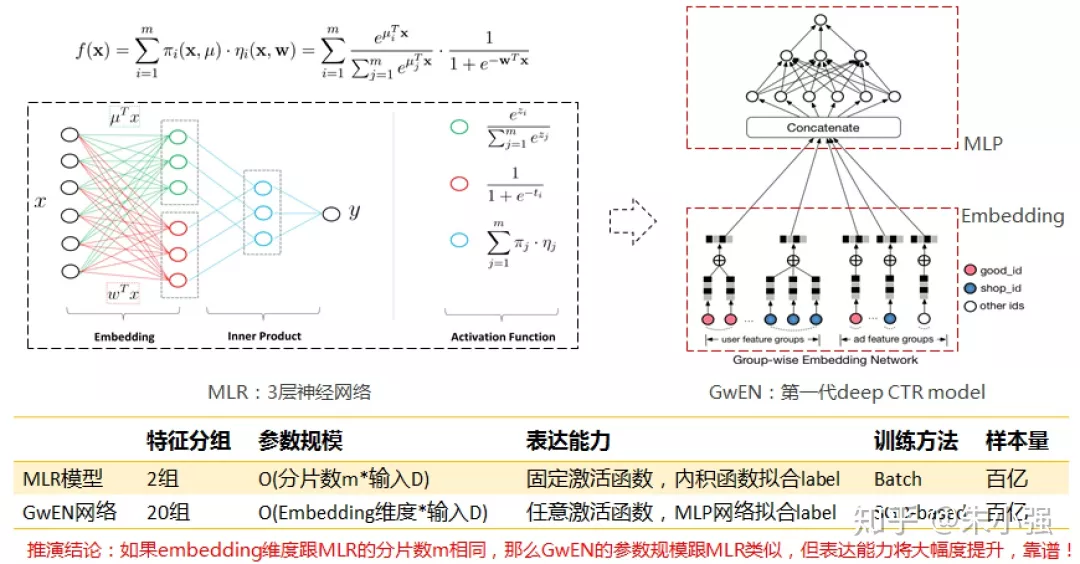 图1:从MLR到第一代端到端深度CTR模型GwEN
图1:从MLR到第一代端到端深度CTR模型GwEN
实践和思考不久催生了突破。16年5-6月份我构思出了第一代端到端深度CTR模型网络架构(内部代号GwEN, group-wise embedding network),如图1所示。对于这个网络有多种解释,它也几乎成为了目前业界各个团队使用深度CTR模型最基础和内核的版本。图1给出了思考过程,应该说GwEN网络脱胎换骨于MLR模型,是我们对互联网尺度离散数据上端到端进行非线性建模的第二次算法尝试。当然跟大规模MLR时期一样,我们再一次遭遇了那三个关键挑战,这里不再赘述。有个真实的段子: 16年6月份我们启动了研发项目组,大约7月份的时候有同学发现G在arxiv上挂出了WDL(wide and deep)那篇文章,网络主体结构与GwEN如出一辙,一下子浇灭了我们当时想搞个大新闻的幻想。客观地讲当时技术圈普遍蔓延着核心技术保密的氛围,因此很多工作都在重复造轮子。16年8月份左右我们验证了GwEN模型大幅度超越线上重度优化的MLR,后来成为了我们第一代生产化deep CTR model。因为WDL的出现我们没对外主推GwEN模型,只作为DIN论文里的base model亮了相。不过我在多次分享时强调,GwEN模型虽看起来简单直接,但是背后对于group-wise embedding的思考非常重要,去年我受邀的一个公开直播中对这一点讲得比较透,感兴趣的同学可以翻阅:GwEN分享资料 https://zhuanlan.zhihu.com/p/34940250
2. 技术拐点:模型工程奠基
GwEN引爆了我们在互联网场景探索DL技术的浪潮,并进而催生了这个领域全新的技术方法论。以阿里定向广告为例,16-17年我们大刀阔斧地完成了全面DL化的变革,取得了巨大的技术和业务收益。如果给这个变革的起点加一个注脚,我认为用”模型工程”比较贴切。这个词是我17年在内部分享时提出来的(不确定是不是业界第一个这么提的人),后来我看大家都普遍接受了这个观点。
如果说大规模浅层机器学习时代的特征工程(feature engineering, FE)是经验驱动,那么大规模深度学习时代的模型工程(model engineering, ME)则是数据驱动,这是一次飞跃。当然ME时代不代表不关注特征,大家熟悉的FE依然可以进行,WDL式模型本来就有着调和feature派和model派的潜台词(听过不同渠道的朋友类似表述,G家的同学可以证实下)不过我要强调的是,传统FE大都是在帮助模型人工预设一些特征交叉关系先验,ME时代特征有更重要的迭代方式:给模型喂更多的、以前浅层模型难以端到端建模的signal(下一节细说),DL model自带复杂模式学习的能力。
说到这,先交代下GwEN/WDL端到端deep CTR model成功后业界的情况:很多技术团队奉WDL为宝典,毕竟G背书的威力非常大。随后沿着“把特征工程的经验搬上DL模型”这个视角相继出了多个工作,如PNN/DeepFM/DCN/xDeepFM等。这些模型可以总结为一脉相承的思路:用人工构造的代数式先验来帮助模型建立对某种认知模式的预设,如LR模型时代对原始离散特征的交叉组合(笛卡尔乘积),今天的DL时代演变为在embedding后的投影空间用內积、外积甚至多项式乘积等方式组合。理论上这比MLP直接学习特征的任意组合关系是有效的——“No Free Lunch"定理。但我经常看到业界有团队把这些模型逐个试一遍然后报告说难有明显收益,本质是没有真正理解这些模型的作用点。
16年底的时候,在第一代GwEN模型研发成功后我们启动了另一条模型创新的道路。业界绝大部分技术团队都已跨入了个性化时代,尤其在以推荐为主的信息获取方式逐渐超越了以搜索为主的信息获取方式时更是明显,因此在互联网尺度数据上对用户的个性化行为偏好进行研究、建模、预测,变成了这个时期建模技术的主旋律之一。具体来说,我们关注的问题是:定向广告/推荐及个性化行为丰富的搜索场景中,共性的建模挑战都是互联网尺度个性化用户行为理解,那么适合这种数据的网络结构单元是什么?图像/语音领域有CNN/RNN等基础单元,这种蕴含着高度非线性的大规模离散用户行为数据上该设计什么样的网络结构?显然特征工程式的人工代数先验是无法给出满意的解答的,这种先验太底层太低效。这个问题我们还没有彻底的认知,探索还在继续进行中,但至少在这条路上我们目前已经给出了两个阶段性成果:
-
DIN模型(Deep Interest Network,KDD’18),知乎@王喆同学有一篇实践性较强的解读,推荐参阅:DIN解读
-
DIEN模型(Deep Interest Evolution Network,AAAI’19),知乎@杨镒铭同学写过详细的解读,推荐阅读:DIEN解读
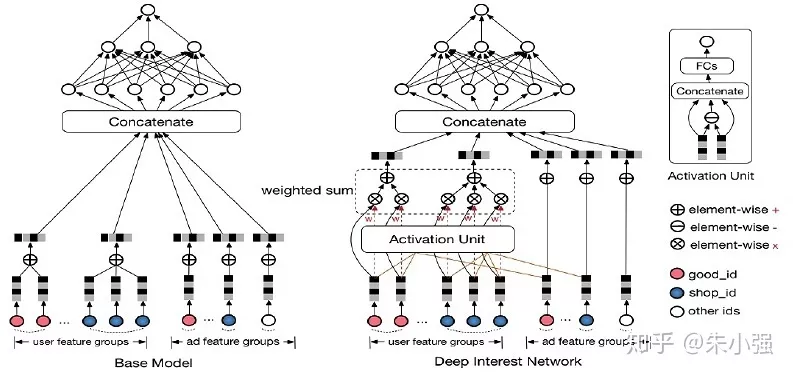 图2:从第一代深度CTR模型GwEN(左)到深度兴趣网络DIN(右)
图2:从第一代深度CTR模型GwEN(左)到深度兴趣网络DIN(右)
DIN/DIEN都是围绕着用户兴趣建模进行的探索,切入点是从我们在阿里电商场景观察到的数据特点并针对性地进行了网络结构设计,这是比人工代数先验更高阶的学习范式:DIN捕捉了用户兴趣的多样性以及与预测目标的局部相关性;DIEN进一步强化了兴趣的演化性以及兴趣在不同域之间的投影关系。DIN/DIEN是我们团队生产使用的两代主力模型,至今依然服务着很大一部分流量。这方面我们还在继续探索,后续进展会进一步跟大家分享。
当然,模型工程除了上述”套路派”之外,还兴起了大一堆”DL调结构工程师”。可以想象很多人开始结合着各种论文里面的基本模块FM、Product、Attention等组合尝试,昏天暗地堆结构+调参。效果肯定会有,但是这种没有方法论的盲目尝试,建议大家做一做挣点快钱就好,莫要上瘾。
3. 技术拐点:超越单体模型的建模套路
模型工程还有另外一个重要延伸,我称之为”超越单体模型”的建模思路,这里统一来介绍下。事实上前面关于模型工程的描述里面已经提到,因为DL模型强大的刻画能力,我们可以真正端到端地引入很多在大规模浅层模型时代很难引入的信号,比如淘宝用户每一个行为对应的商品原图/详情介绍等。
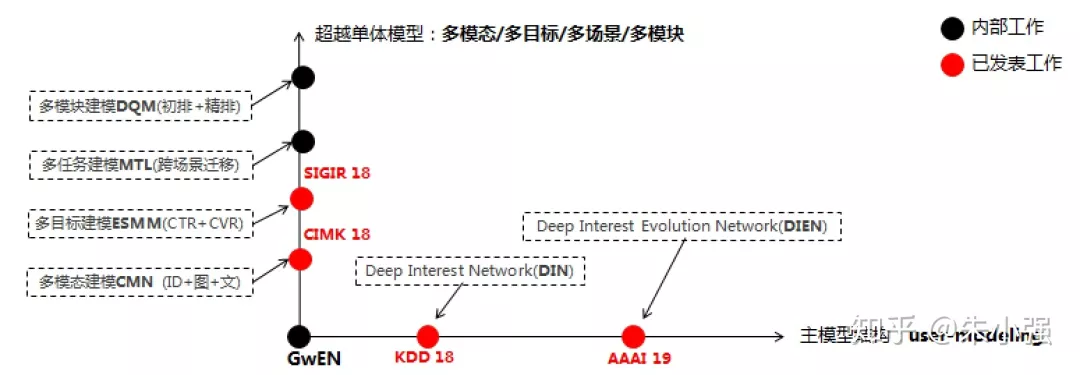 图3:深度CTR模型演化双轨道
图3:深度CTR模型演化双轨道
图3给出了我们团队建模算法的整体视图。主模型结构在上一节已经介绍,与其正交的是一个全新的建模套路:跳出上一时代固化的建模信号域,开辟新的赛道——引入多模态/多目标/多场景/多模块信号,端到端地联合建模。注意这里面关键词依然是端到端。两篇工作我们正式对外发表了,包括:
-
ESMM模型(Entire-Space Multi-task Model, SIGIR’18),知乎@杨旭东同学写过详细的解读并给出了代码实现,推荐参阅:ESMM解读 https://zhuanlan.zhihu.com/p/37562283
-
CrossMedia模型(论文里面叫DICM, Deep Image CTR Model, CIKM’18),这个工作结合了离散ID特征与用户行为图像两种模态联合学习,模型主体采用的是DIN结构。最大的挑战是工程架构,因此论文详细剖析了我们刚刚开源的X-DeepLearning框架中,超越PS的AMS组件设计。不过目前好像没看到有人解读过,感兴趣的同学可以读一读写个分析。
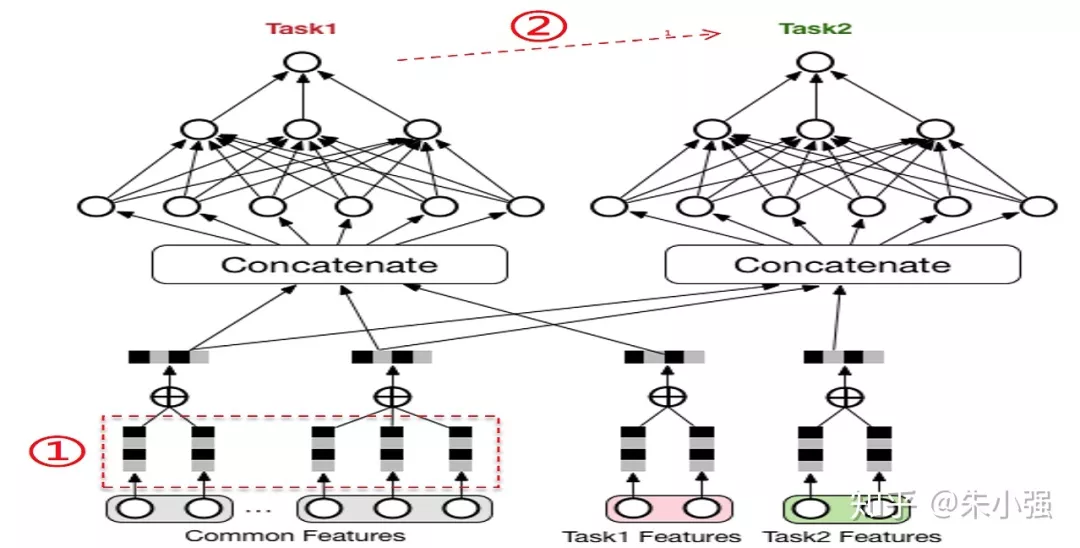 图4:深度学习时代Multi-Task Learning建模范式
图4:深度学习时代Multi-Task Learning建模范式
关于ESMM模型多说两句,我们展示了对同态的CTR和CVR任务联合建模,帮助CVR子任务解决样本偏差与稀疏两个挑战。事实上这篇文章是我们总结DL时代Multi-Task Learning建模方法的一个具体示例。图4给出了更为一般的网络架构。据我所知这个工作在这个领域是最早的一批,但不唯一。今天很多团队都吸收了MTL的思路来进行建模优化,不过大部分都集中在传统的MTL体系,如研究怎么对参数进行共享、多个Loss之间怎么加权或者自动学习、哪些Task可以用来联合学习等等。ESMM模型的特别之处在于我们额外关注了任务的Label域信息,通过展现>点击>购买所构成的行为链,巧妙地构建了multi-target概率连乘通路。传统MTL中多个task大都是隐式地共享信息、任务本身独立建模,ESMM细腻地捕捉了契合领域问题的任务间显式关系,从feature到label全面利用起来。这个角度对互联网行为建模是一个比较有效的模式,后续我们还会有进一步的工作来推进。
应该要指出MTL的应用范围极广,如图3中我们的过往工作。它尤其适合多场景、多模块的联动,典型的例子是数据量较大的场景可以极大地帮助小场景优化。此外MTL这类模型工程解法与上一节介绍的单模型结构设计可以互补和叠加,两者的发展没有先后关系、可以并行推进。
4. 技术拐点:嵌入工程系统的算法设计
实际的工业系统,除了上面抽象出来的CTR预估问题,还有很多独立的话题。介绍下我们在既有系统架构中算法层面的一些实践。以广告系统为例,从算法视角来看至少包括以下环节:匹配>召回>海选>粗排>精排>策略调控,这些算法散落在各个工程模块中。现在让我们保持聚焦在CTR相关任务,看看在系统中不同的阶段都可以有哪些新的变化。几个典型的系统瓶颈:海选/粗排所在的检索引擎,精排所在的在线预估引擎,以及这些算法离线所依赖的模型生产链路。在DL时代以前,技术已经迭代形成了一些既有的共识,如检索引擎性能关键不宜涉及复杂的模型计算。但是跨入DL时代后,既有的共识可以被打破、新的共识逐渐形成。
4.1 海选/粗排的复杂模型化升级
在我们原有的系统中,检索过程中涉及到的排序是用一个静态的、非个性化的质量分来完成,可以简单理解为广告粒度的一个统计分数,显然跟精排里面我们采用的各种各样复杂精细的模型技术(前几节的内容)相比它很粗糙。据我了解业界也有团队用了一些简化版的模型,如低配版LR模型来完成这个过程。背后的核心问题是检索时候选集太大,计算必须精简否则延迟太长。图5给出了我们升级后的深度个性化质量分模型,约束最终的输出是最简单的向量內积。这种设计既迎合了检索引擎的性能约束,同时实测跟不受限DL模型(如DIN)在离线auc指标上差距不太显著,但比静态模型提升巨大。
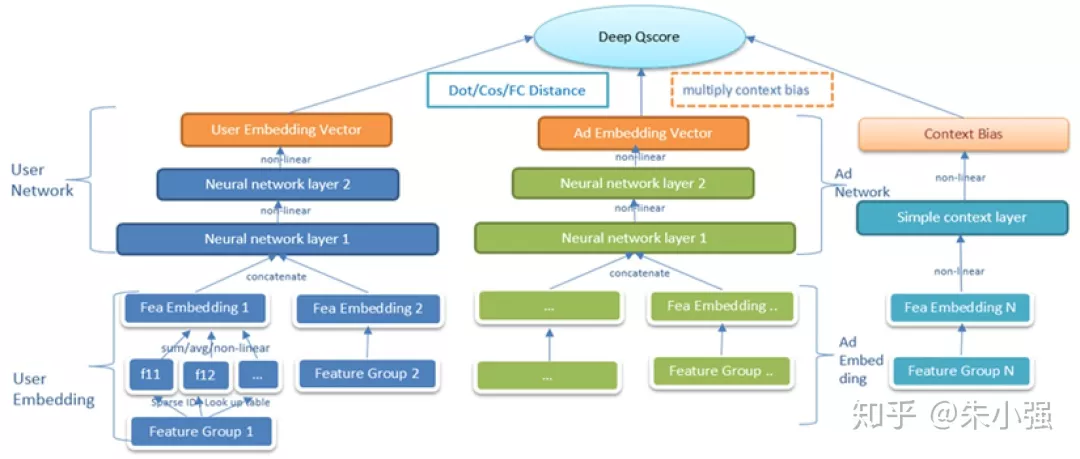 图5:深度个性化质量分模型DQM
图5:深度个性化质量分模型DQM
这里有两个延伸: 1) 海选/粗排DQM模型只帮助缩减候选集规模,不作为最终广告的排序分,因此它的精度可以不像精排模型那样追求极致,相应地多考虑系统性能和数据循环扰动;2) DQM模型对于检索匹配召回等模块同样适用,例如现在很多团队已经普通接受的向量化召回架构,跟DQM在模型架构上完全吻合。只不过作用在召回模块,其建模信号和训练样本有很大的不同,更多地要考虑用户兴趣泛化。提到向量化高效计算,F/M两家都开源了优秀的架构,推荐大家参阅:faiss https://github.com/facebookresearch/faiss 和 SPTAG https://github.com/Microsoft/SPTAG
4.2 面向在线预估引擎的模型压缩
在LR/MLR时代在线预估引擎的计算相对简单、压力不大。但当复杂的DL模型层出不穷后,在线引擎的算力瓶颈凸显。为了缓解这个问题,我们在17年试水了一个工作:轻量级模型压缩算法(Rocket Training, AAAI'18),形象地称之为无极调速模式。知乎上没看到到位的解读,这里放出一作@周国瑞同学自己的文章:Rocket Training解读 https://zhuanlan.zhihu.com/p/28625922
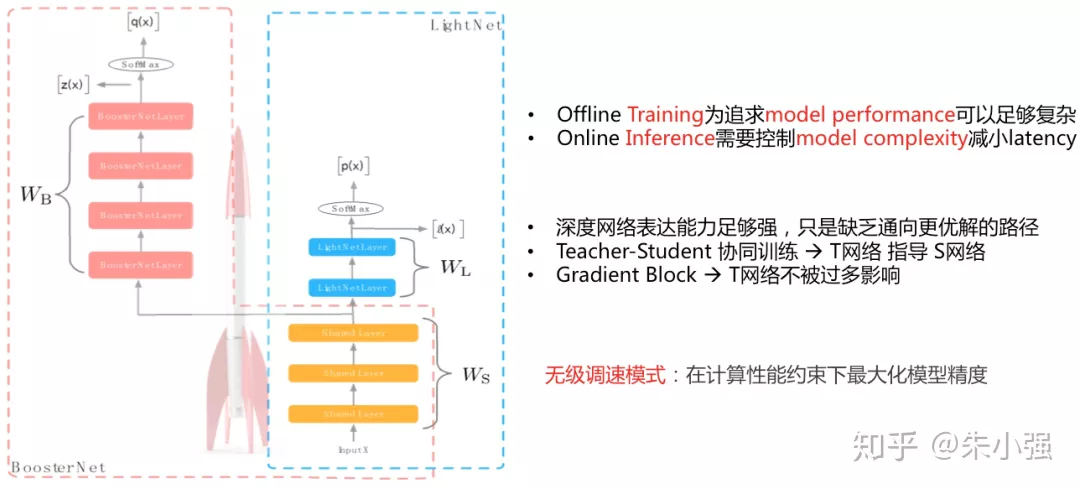 图6:轻量级模型压缩算法Rocket Training
图6:轻量级模型压缩算法Rocket Training
DL模型的over-parameterization使得我们可以通过不同的优化方法寻找更好的解路径,Rocket只是一条,未来在这个方向上我们还会有更多的工作。但有可以肯定模型DL化带来的在线预估引擎的算力瓶颈是一个新常态,这个方向上会引起更大的关注并演化成新一代系统架构。
4.3 打破资源依赖的增量/实时化算法架构
DL模型的复杂化除了带来在线预估引擎的性能挑战外,对离线生产链路的资源挑战也急剧放大。容易理解的是全量模型的训练时间及占用机器规模肯定会逐步增加,同时模型的并行研发规模也会大增,即:”模型个数x模型时长x机器规模”全面膨胀。在这种情况下增量/实时模型训练架构就成为了胜负手。虽然业界很多时效性强的场景(如信息流)online模型的效果收益是巨大和关键的,但这里我不想过多地强调效果层面的收益,而更愿意从资源架构层面做探讨。虽然DL模型采用了sgd-based优化算法,直觉来看batch训练和incremental或online训练应该同构。然而ODL(Online Deep Learning)所存在的问题和挑战绝不止于此,且它跟LR时代的Online Learning有很多的差异性。目前同时完成了全面DL并进而ODL化的团队不太多。当然也有团队是从OL系统直接向ODL升级的,这个路径固然看似更快捷,但也许错过了DL模型盛宴的不少美妙菜肴——batch训练是纯模型探索的更优土壤。我们从17年底开始从DL到ODL升级,18年初落地、经历了18年双十一大促,我认为只是刚刚走完了ODL的最基础阶段,这方面我们还在持续推进,19年会有新工作跟大家分享。
5. 一些Tips
到这里为止,差不多是我开篇所述的DL技术轮子旋转的第一圈位置。洋洋洒洒地写了一大堆,如果坚持看到这里的读者,那一定是极有耐心。此处给大家总结一些实践原则建议。
-
大厂为追求最高的收益可以选用复杂的技术,尤其是像广告这样的部门,资源和人力投入的性价比超值。但对于小厂技术储备和投入相对不足,上面介绍的大量精细工作其实很难实施。模型架构层面一个可行的建议是:采用DQM式结构,把user/ad/query或上下文统一嵌入到vector空间,然后用向量计算架构进行在线服务。好处是在线预估系统可以极简,从而可以集中精力到离线的特征/模型调优,rocket/MTL等协同网络架构都是可以尝试的点,这可以保障轻松拿到业务效果的第一桶金;
-
如果是规模化的算法团队,愿意投入DL算法的设计,建议: 参考而绝不要盲信现有paper里面的架构,不要再把WDL/DIN等这类已有工作当成宝典。我的观点是,DL时代model这个词已经虚化了,像浅层模型时代LR/MLR等固定的模型已经不存在。模型是死的,场景是活的,遵循一定的规律、充分了解你的领域数据特点,吸收DIN/DIEN/ESMM这类方法的思考套路,定制适合具体问题的网络结构;
-
再进一步,如果是中大型有较强的实力掌控技术大盘的团队,建议牢记”算法-系统-架构”一体化的理念和方法论,DL对广告/推荐/搜索这类典型互联网应用系统的技术改造是全面而彻底的,现今的系统和架构大都是浅层模型时代遗留的产物,今天面临着复杂算法、异构硬件的多重冲刷,是时候打破旧规则,建立全新的基础设施;
-
特别聚焦到CTR预估技术上,离散特征的丰富性跟DL模型的效果密切相关,如果本身是容量很低的特征表达,模型是很难发挥的。例如我知道不少团队拿大量的低维统计特征为主的数据喂给DL模型,结果发现没什么效果,这显然是不得要领。“特征-模型-样本”是机器学习三要素,要时刻牢记。建议有实力有需求的团队,尽量充分地拓展更丰富的特征表达和样本信息容量,给模型创造更大的发挥空间;
-
以上所有建议都有一个重要的前提——自动化的算法迭代和生产链路。这件事在LR模型时代还没那么突出,因为算法迭代速度快不起来,但是在DL模型时代算法的开发和试错成本很低,完整的自动化链路才能真正发挥算法的威力,否则陷入各种在/离线手工胶水代码、人肉debug的汪洋大海,只能望洋兴叹了。
-
少重复造轮子,多拥抱开源。贡献开源或者从开源技术中吸取最新成果高起点迭代。打个硬广,我们最近刚把上述大部分技术统一整理集成为阿里开源项目X-DeepLearning(XDL)。XDL项目包含了我们对大规模分布式DL训练框架、各种实战自研模型(囊括了前述大部分模型)、高性能在线serving引擎为一体的工业级深度学习解决方案,感兴趣的同学可以了解下,开源项目地址:
三、小趋势
DL技术的兴起,给这个领域的算法工程师创造了巨大的施展空间,集结了信号迭代(特征+样本)的模型工程是升维攻击,技术演化如脱缰的骏马尽情驰骋——这是DL驱动的技术变革。有个量化的指标:DL以前我们团队专业的机器学习平台小组要花费好几个月时间才研发出大规模分布式MLR模型,今天我们刚入职的新同学分分钟能够写出跑在同样规模数据上的各种模型,并可以根据灵感随时进行算法创作,这就是DL工具化所带来的生产力巨大飞跃。这个阶段我称之为深度学习1.0时代。在互联网领域DL-1.0时代的起点是从15-16年左右开始,目前第一梯队的团队大都完成或即将完成1.0的全面DL化。我们团队在17年底18年初已经大致完成了这个过程,上面介绍的工作大都是17年就已经完成的。
凡是过往,皆为序曲。DL-1.0引发的技术飞跃,算法创新出现了数量级式的爆炸增长,一方面极大地推进了业务效果的提升速度和高度,另一方面带来了立体化的全栈技术挑战。如前面所述,我们已经试图迎合DL算法对依赖的系统和架构做了一些改造,但这还不足以完全抵御算法爆炸所带来的冲击。18年我们开始面临了一些新瓶颈、加上对DL技术本身有了更多的实践认知,这些输入兵合一处,推动着我们向新的阶段迈进。这个新阶段我称之为深度学习2.0时代。套用卖中年保健品的罗胖对未来的预测,谈谈我们看到的小趋势
-
DL模型本身更精细化的解剖。16年端到端DL刚起步的时候,我们常把DL是实验科学挂在嘴边。但是经历了2年的高速发展,我们对DL模型的常见性态已经有了基本的掌握。下一阶段,对DL模型内在结构更精细的认知,将成为推动DL-2.0阶段算法架构升级的起点;
-
Data-driven的方法论缺陷。互联网用户行为理解是非完全信息建模问题,当算法发展到一定高度时,信息容量本身的固有不足将成为制约。今年学术界不少大佬开始讨论”物理世界模型”,我认为也是在反思Data-driven的不足。我也考虑过能否构建这个领域的物理世界模型,如最近又火了的Knowledge Graph,确实有助于帮助建立一些common sense的认知,但互联网领域是”人-信息-系统”的有机结合体,世界上最睿智的人恐怕也很难理清楚大数据里个人行为背后的动机,换句话说完全的”物理世界模型”应该不可行。歪一下楼,关于推荐系统的可解释性现在也有很多的讨论,我认为真正能够大规模工业应用的充分可解释模型是不现实的,因为训练模型的数据本身都很难有完全合理的解释,当然部分的因果或者关联解释应该是行得通的。回到主题,既然Data-driven方法受data制约,我们认为DL-2.0阶段对更完备连贯的用户行为数据串联,将有助于算法的进一步提升;
-
算法复杂度持续指数级增长,资源&算力全面告急,algo-system的co-design从口号变成胜负手。DL-2.0阶段ODL架构将全面串联”算法建模-离线系统-在线引擎”,形成标配解法。这个阶段技术性价比将纳入严肃讨论的范畴。回归技术的本源:什么叫做创新?用简洁低成本的方式优雅地解决问题,取得最好的效果。
-
DL本身从1.0阶段fancy的明星技术变成2.0阶段的基础设施。DL-2.0将更多地聚焦到领域问题本身,除了持续的效果提升外,工具的顺手将带来新的业务可能性,诸如冷启动、数据循环、推荐新颖性等硬核问题将会有新的思考和实践。
四、结束语
DL是对以用户个性化建模为代表的互联网应用技术的一次全新洗礼:从建模思路,训练系统,到服务引擎,短时间内进行了一次彻底的全栈升级,复杂度远大于历史上的技术变化。2015年以前的10多年时间,大规模机器学习统治着业界;2016年后大规模深度学习技术成为了主旋律,且短短2年多时间就取得了显著的成就。跟媒体热炒、难落地的AI潮不同,在这个领域中以DL为首的技术升级已经实实在在带来了真金白银。DL已经从最初的特定model升级为一种methodology。model易旧,套路永存。如前文反复强调,DL时代没有固定的模型,只有可借鉴的建模范式。
DL-1.0时代,由算法的代差式升级驱动了全局变化。抛开纷繁复杂的算法或者系统架构,这个阶段有一个核心的关键词:端到端。
DL-2.0时代,我预判由算法的可迭代性驱动。聪明的读者们,这个阶段关键词是什么呢?
五、参考文献
1. MLR: “Learning Piece-wise Linear Models from Large Scale Data for Ad Click Prediction”
2. WDL: “Wide and Deep Learning for Recommender Systems”
3. DeepFM: “DeepFM: A Factorization-Machine based Neural Network for CTR Prediction”
4. PNN: “Product-based Neural Network for User Response Prediction”
5. DCN: _”Deep & Cross Network for Ad Click Prediction” _
6. xDeepFM: “xDeepFM: Combining Explicit and Implicit Feature Interactions for Recommender Systems”
7. DIN: “Deep Interest Network for Click-Through Rate Prediction”
8. DIEN: “Deep Interest Evolution Network for Click-Through Rate Prediction”
9. ESMM: “Entire Space Multi-Task Model: An Effective Approach for Estimating Post-Click Conversion Rate”
10. Rocket Training: “Rocket Launching: A Universal and Efficient Framework for Training Well-performing Light Net”
作者介绍:
朱小强(阿里花名: 怀人
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E8%A1%8C%E7%9F%A5%E9%95%B6%E5%B5%8C%E5%9C%A8%E4%BA%92%E8%81%94%E7%BD%91%E6%8A%80%E6%9C%AF%E4%B8%8A%E7%9A%84%E6%98%8E%E7%8F%A0%E6%BC%AB%E8%B0%88%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0%E6%97%B6%E4%BB%A3%E7%82%B9%E5%87%BB%E7%8E%87%E9%A2%84%E4%BC%B0%E6%8A%80%E6%9C%AF%E8%BF%9B%E5%B1%95/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


