语音识别微软亚研自动语法纠错系统达到人类水平
因为 seq2seq 模型在语法纠错上存在缺陷,微软亚洲研究院的自然语言计算团队近日提出了流畅度提升学习和推断机制,用于改善 seq2seq 模型的语法纠错性能。实验表明,改进后的模型取得了当前最佳性能,并首次在两个基准上都达到了人类水平。
用于语法纠错(GEC)的序列到序列(seq2seq)模型(Cho et al., 2014; Sutskever et al., 2014)近年来吸引了越来越多的注意力(Yuan & Briscoe, 2016; Xie et al., 2016; Ji et al., 2017; Schmaltz et al., 2017; Sakaguchi et al., 2017; Chollampatt & Ng, 2018)。但是,大部分用于 GEC 的 seq2seq 模型存在两个缺陷。第一,seq2seq 模型的训练过程中使用的纠错句对有限,如图 1(a)所示。受训练数据的限制,具备数百万参数的模型也可能无法实现良好的泛化。因此,如果一个句子和训练实例有些微的不同,则此类模型通常无法完美地修改句子,如图 1(b)所示。第二,seq2seq 模型通常无法通过单轮 seq2seq 推断完美地修改有很多语法错误的句子,如图 1(b)和图 1(c)所示,因为句子中的一些错误可能使语境变得奇怪,会误导模型修改其他错误。

图 1:(a)纠错句对;(b)如果句子与训练数据有些微的不同,则模型无法完美地修改句子;(c)单轮 seq2seq 推断无法完美地修改句子,但多轮推断可以。
为了解决上述限制,微软研究者提出一种新型流畅度提升学习和推断机制,参见图 2。
对于流畅度提升学习,seq2seq 不仅使用原始纠错句对来训练,还生成流畅度较差的句子(如来自 n-best 输出的句子),将它们与训练数据中的正确句子配对,从而构建新的纠错句对,前提是该句子的流畅度低于正确句子,如图 2(a)所示。研究者将生成的纠错句对称为流畅度提升句对(fluency boost sentence pair),因为目标端句子的流畅度总是会比源句子的流畅度高。训练过程中生成的流畅度提升句对将在后续的训练 epoch 中作为额外的训练实例,使得纠错模型可以在训练过程中看到具有更多语法错误的句子,并据此提升泛化能力。
对于模型推断,流畅度提升推断机制允许模型以多轮推断的方式渐进地修改句子,只要每一次提议的编辑能够提升语句的流畅度,如图 2(b) 所示。对于有多个语法错误的语句,一些错误将优先得到修正。而经修正的部分能让上下文更加清晰,这对模型接下来修改其它错误非常有帮助。此外,由于这种任务的特殊性,我们可以重复编辑输出的预测。微软进一步提出了一种使用两个 seq2seq 模型的往返纠错方法,其解码顺序是从左到右和从右到左的 seq2seq 模型。又因为从左到右和从右到左的解码器使用不同的上下文信息解码序列,所以它们对于特定的错误类型有独特的优势。往返纠错可以充分利用它们的优势并互补,这可以显著提升召回率。
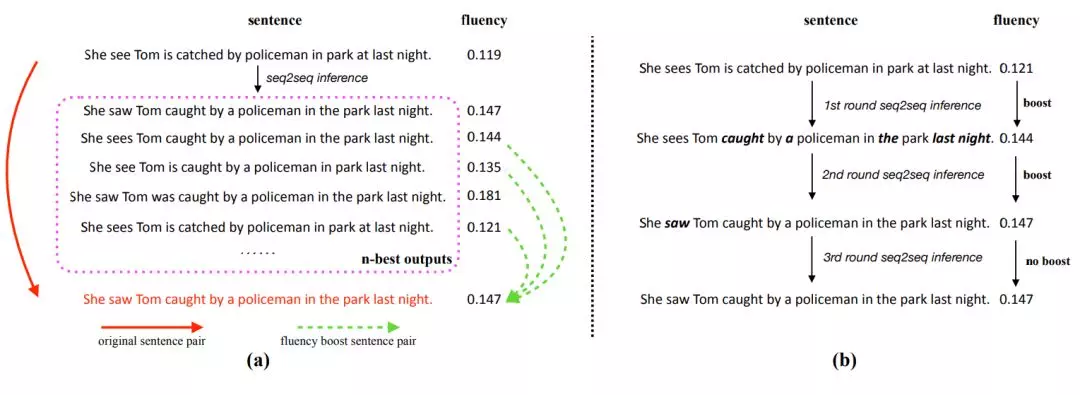
图 2:流畅度提升学习和推断机制:(a)给出一个训练实例(即纠错句对),流畅度提升学习机制在训练过程中从 seq2seq 的 n-best 输出中构建多个流畅度提升句对。流畅度提升句对将在后续的训练 epoch 中用作训练实例,帮助扩展训练集,帮助模型学习;(b)流畅度提升推断机制允许纠错模型通过多轮 seq2seq 推断渐进式地修改句子,只要句子的流畅度一直能够提升。
结合流畅度提升学习和推断与卷积 seq2seq 模型,微软亚洲研究院取得了当前最佳的结果,这使其成为首个在两个基准上都达到人类水平的 GEC 系统。
论文:REACHING HUMAN-LEVEL PERFORMANCE IN AUTOMATIC GRAMMATICAL ERROR CORRECTION: AN EMPIRICAL STUDY

论文地址: https://arxiv.org/pdf/1807.01270.pdf
摘要:神经序列到序列(seq2seq)方法被证明在语法纠错(GEC)中有很成功的表现。基于 seq2seq 框架,我们提出了一种新的流畅度提升学习和推断机制。流畅度提升学习可以在训练期间生成多个纠错句对,允许纠错模型学习利用更多的实例提升句子的流畅度,同时流畅度提升推断允许模型通过多个推断步骤渐进地修改句子。结合流畅度提升学习和推断与卷积 seq2seq 模型,我们的方法取得了当前最佳的结果:分别在 CoNLL-2014 标注数据集上得到 75.02 的 F0.5 分数,在 JFLEG 测试集上得到 62.42 的 GLEU 分数,这使其成为首个在两个基准数据集上都达到人类水平(CoNLL72.58,JFLEG62.37)的 GEC 系统。
2 背景:神经语法纠错
典型的神经 GEC 方法使用带有注意力的编码器-解码器框架将原始句子编辑成语法正确的句子,如图 1(a)所示。给出一个原始句子
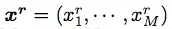 及其纠错后的句子
及其纠错后的句子
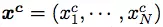 ,其中
,其中
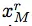 和
和
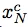 分别是句子 x^r 和 x^c 的第 M 和第 N 个单词,则纠错 seq2seq 模型通过最大似然估计(MLE)从纠错句对中学习概率映射 P(x^c |x^r ),进而学习模型参数 Θ_crt 以最大化以下公式:
分别是句子 x^r 和 x^c 的第 M 和第 N 个单词,则纠错 seq2seq 模型通过最大似然估计(MLE)从纠错句对中学习概率映射 P(x^c |x^r ),进而学习模型参数 Θ_crt 以最大化以下公式:
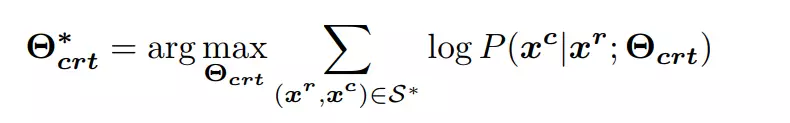
其中 S* 表示纠错句对集。
对于模型推断,通过束搜索输出句子选择
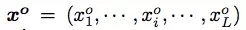 ,这一过程需要最大化下列公式:
,这一过程需要最大化下列公式:
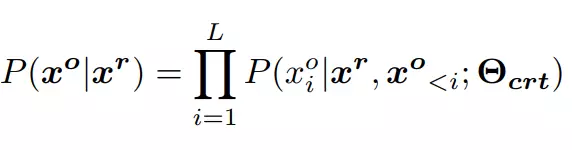
3 流畅度提升学习
用于 GEC 的传统 seq2seq 模型仅通过原始纠错句对学习模型参数。然而,这样的纠错句对的可获得性仍然不足。因此,很多神经 GEC 模型的泛化性能不够好。
幸运的是,神经 GEC 和神经机器翻译(NMT)不同。神经 GEC 的目标是在不改变原始语义的前提下提升句子的流畅度;因此,任何满足这个条件(流畅度提升条件)的句子对都可以作为训练实例。
在这项研究中,研究者将 f(x) 定义为句子 x 的流畅度分数。
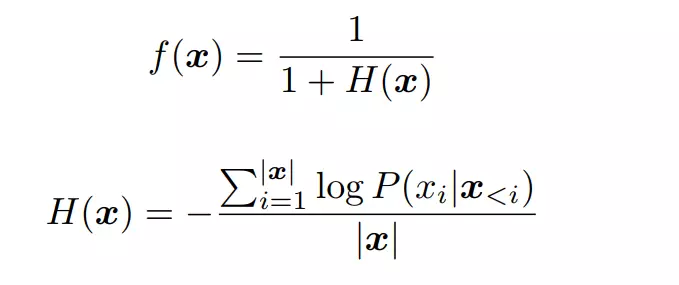
其中,P(x_i | x_
流畅度提升学习的核心思想是生成流畅度提升的句对,其在训练期间满足流畅度提升条件,如图 2(a)所示,因此这些句子对可以进一步帮助模型学习。
在这一部分中,研究者展示了三种流畅度提升策略:反向提升(back-boost)、自提升(self-boost)和双向提升(dual-boost),它们以不同的方式生成流畅度提升句子对,如图 3 所示。
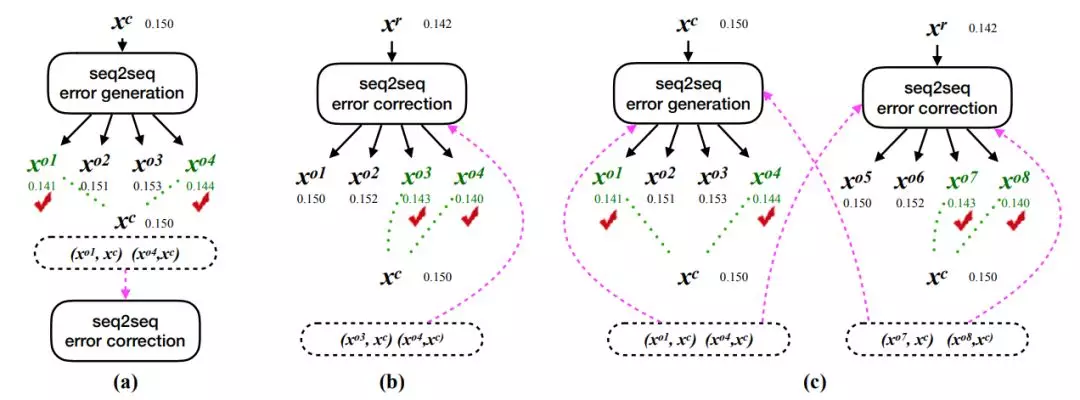 图 3:三种流畅度提升学习策略:(a)反向提升,(b)自提升,(c)双向提升。它们都能生成流畅度提升句对(虚线框中的句对),帮助训练过程中的的模型学习。图中的数字是对应句子的流畅度分数。
图 3:三种流畅度提升学习策略:(a)反向提升,(b)自提升,(c)双向提升。它们都能生成流畅度提升句对(虚线框中的句对),帮助训练过程中的的模型学习。图中的数字是对应句子的流畅度分数。
4 流畅度提升推断
4.1 多轮纠错
正如在第一节中讨论的,一些具有多个语法错误的语句通常不能通过一般的 Seq2Seq 推断(单轮推断)得到完美的修正。幸运的是,神经 GEC 与 NMT 不同,它的源语言与目标语言相同。这一特征允许我们通过多轮模型推断多次编辑语句,也就产生了流畅度提升推断过程。如图 2(b) 所示,流畅度提升推
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E8%AF%AD%E9%9F%B3%E8%AF%86%E5%88%AB%E5%BE%AE%E8%BD%AF%E4%BA%9A%E7%A0%94%E8%87%AA%E5%8A%A8%E8%AF%AD%E6%B3%95%E7%BA%A0%E9%94%99%E7%B3%BB%E7%BB%9F%E8%BE%BE%E5%88%B0%E4%BA%BA%E7%B1%BB%E6%B0%B4%E5%B9%B3/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


