金融风控大厂道精选面试题分享
问题1:深度学习的风控模型,从经验上看,样本量大概要多少条啊
解析:不同的模型不一样,而且也不光要注意样本量,比如RNN其实希望序列长度至少在12个月以上,粗略的说,样本量五十万以上效果比较好。
问题2:5万正样本,200负样本,B卡,不只是提高额度,会拒绝一部分客户,怎么建模?
5万负样本是没有做下采样的必要的,200正样本无论用什么方法做过采样说实话由于自身携带的信息量比较少,学习的应该也不是完全的。所以这时候建议先略作改动,评价函数加一项,负样本的召回率,也就是说这时候不是主要关注KS,而是对负样本究竟能抓到多少。
然后负样本学习的时候一定要加权,权重就按照sklearn中逻辑回归默认的balanced方法就ok,而且如果是我可能生成一个决策树,把坏账从0.4%下降到0.12%左右我觉得就蛮好的了
文末免费送电子书:七月在线干货组最新 升级的《名企AI面试100题》免费送!
问题3:对短信打标签,也就是判断出短信属于的标签是哪一类,这样一个任务是提取文本关键词的任务吧?
解析:
我建议先确定每个词对每个类别的贡献度。简单来做就是每种类别找几个词,手动划分一下有这个词,就属于这个类别。复杂一点来做,就训练个模型,确定每个词对每种类别的贡献度,然后对每条记录做个预测,排名前几的标签都给他。
问题4:为什么说准入规则,pre-A, 反欺诈规则反欺诈引擎,还有风控模型,一般都不会选用相同的特征?因为客户群体会越来越少么
基本上每个机器学习模型或多或少都会遇到我们这种问题。我们一般是不会用相同的特征做重复筛选的。这样会导致样本偏移更严重。
就是说,被拒绝的人,是由于某些特征表现差,被拒绝的,那随着时间推移,下次建模的样本里面,就没有这些人了…这些这些特征上的样本分布就变了。
给大家分享一个面试秘籍【LintCode直播刷题 - Java版】
课程精炼浓缩Java数据结构与常用面试算法知识点,结合面试真题,做到真正面向面试编程,用最短时间提升算法与数据结构水平,搞定大厂面试。
课程链接: https://www.julyedu.com/course/getDetail/358
问题5:在ks上训练集和测试集相差不大,但在auc上却相差较大,这是为啥?
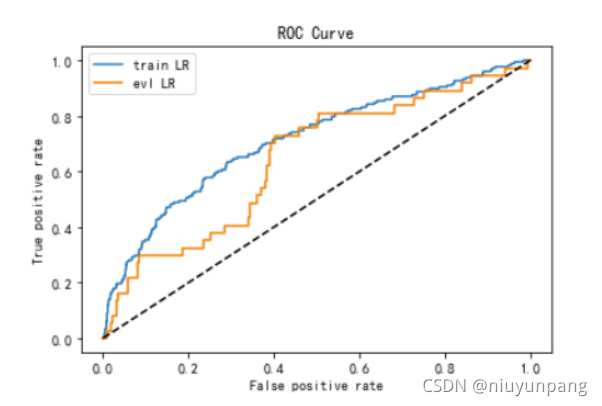
解析:
下图中两条红线分别表示训练集和测试集KS的差距,看起来两者是差不多的,曲线下的面积表示的是两者的AUC值,很明显两者的AUC差的就很多了,由于ks值能找出模型中差异最大的一个分段,因此适合用于cut_off,像评分卡这种就很适合用ks值来评估。但是ks值只能反映出哪个分段是区分最大的,而不能总体反映出所有分段的效果,因此AUC值更能看出总体的效果。
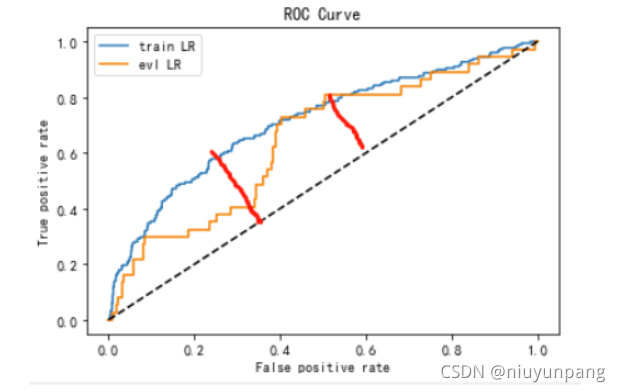
解析2
下面详细说明下AIC和KS的关系
,商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


