知其然知其所以然基于多任务学习的可解释推荐系统
本文是工业界和学术界共同合作的产物。Layer 6 AI 和 University College Dublin 的科学家们提出一种 通过整合矩阵分解(MF)模型和对抗式 Seq2Seq 模型的多任务学习框架,并利用强化学习来尝试生成评论,借以解答推荐系统的研究和应用领域一种“殿堂”级的难题——推荐系统的评分预测的可解释性。除此之外,该模型的预测准确性超过了现有推荐模型的效果。
作者丨姜松浩
学校丨中国科学院计算技术研究所硕士
研究方向丨机器学习、数据挖掘

模型结构
该多任务学习的推荐模型架构可分为两个部分:
第一部分为利用 对抗式的 Seq2Seq 模型 学习生成用户对 item 的相关的个性化评论,将此评论作为模型推荐的潜在特征模型生成的可解释依据;
第二部分为一种 内容敏感型 PMF 模型 通过评论文本学习合并的潜在 item 特征,最终通过一种妥协的同步学习方式完成目标,整体结构如下图所示。
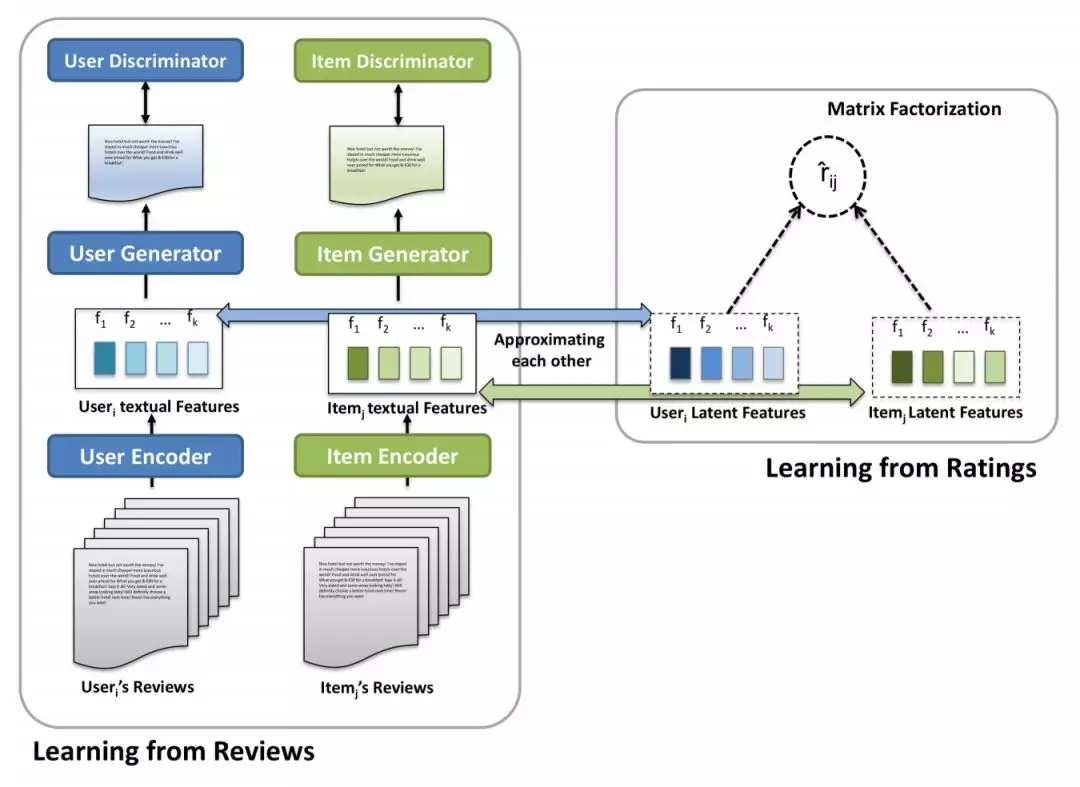
对抗式Seq2Seq
这部分模型的输入可分为两部分,一部分为 用户的评论数据,例如用户 i 的评论文章定义为
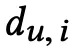 ,这部分数据用来表示用户的偏好。另一部分为** item 的评论数据**,item j 的评论数据定义为
,这部分数据用来表示用户的偏好。另一部分为** item 的评论数据**,item j 的评论数据定义为
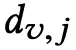 ,这部分数据则表示为 item 的情况。
,这部分数据则表示为 item 的情况。
模型结构方面,针对用户的 Seq2Seq 与针对 item 的 Seq2Seq 结构一致,但其参数略有不同。经典的 Seq2Seq [2] 会存在先验的标注情况,但是这种方式会导致 exposure bias 这样的问题。exposure bias 就是说后一项预测依赖于前一项的预测情况,随着时间的推测,这种方式导致错误会逐渐发生积累和偏移。
这篇文章中提出的 Seq2Seq 的方式与经典的 Seq2Seq 不同。文章首创一种 对抗式 Seq2Seq 模型,与常见的 GAN 方式一样包括判别网络和生成网络。
生成模型部分,该部分与经典的 Seq2Seq 基本一致,用来生成相关评论。首先将一条评论中的一系列词汇利用预训练的 Word2Vec 的方式表征为 k 维的向量,然后利用双向 GRU 单元得到潜在的向量
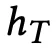 ,该向量为双向
,该向量为双向
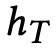 的 concat 结果。将用户 i 发布的所有评论向量 h 进行平均计算得出关于用户的特征
的 concat 结果。将用户 i 发布的所有评论向量 h 进行平均计算得出关于用户的特征
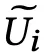 。
。
在 t 时刻,首先将预测的词
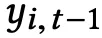 映射为对应的
映射为对应的
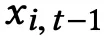 然后与用户特征
然后与用户特征
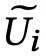 进行 concat 组成 decoder 的 GRU 部分的输入,获得的隐藏层向量 h 经过一层矩阵相乘处理后,利用 Softmax 函数进行概率预测得出 t 时刻的预测词
进行 concat 组成 decoder 的 GRU 部分的输入,获得的隐藏层向量 h 经过一层矩阵相乘处理后,利用 Softmax 函数进行概率预测得出 t 时刻的预测词
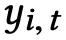 。其概率预测方式如下公式所示。此外,初始化时为隐藏层向量为 0 向量。
。其概率预测方式如下公式所示。此外,初始化时为隐藏层向量为 0 向量。
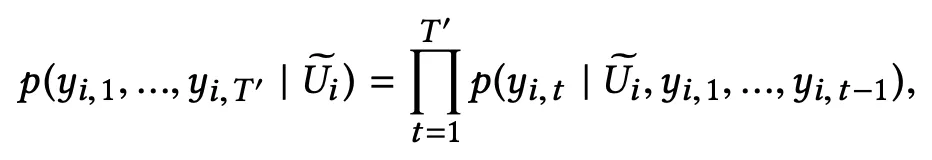
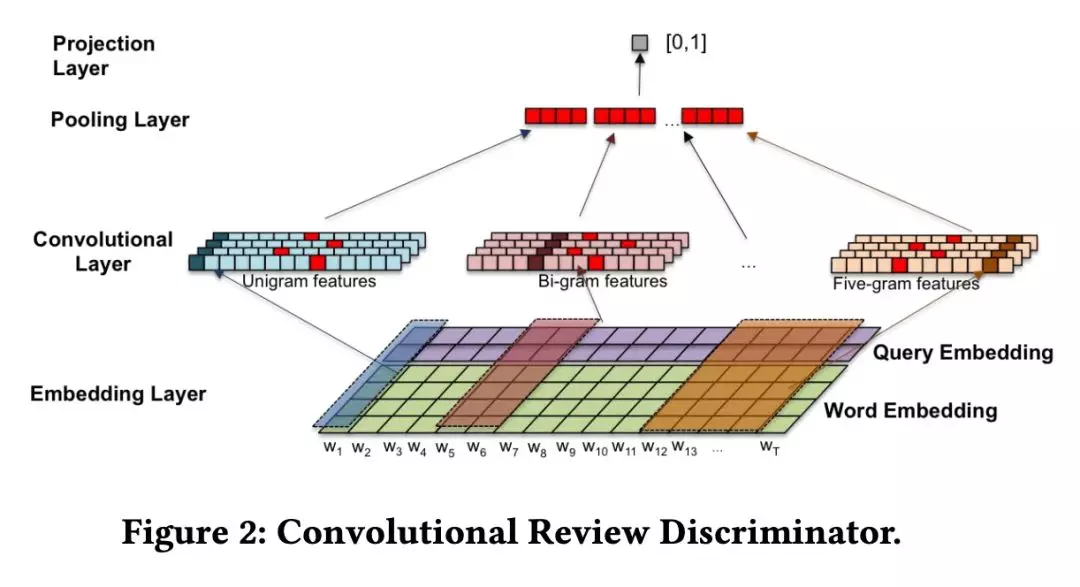
判别模型部分,这篇论文的判别的模型目的与常见的判断文本是不是由人生成的不同,这篇轮的判别目的不仅在于是不是由人生成的,还在于生成的文本与观察的内容主题是不是一致。该部分模型借鉴经典的 TextCNN [3] 结构进行判别,将评论词汇向量与用户特征向量进行 Concat 处理后作为输入,模型结构如下所示。
利用强化学习训练对抗结构。论文将生成模型 G 作为强化学习的 agent,而判别模型 D 的置信概率作为奖励,生成的评论越能欺骗 D 奖励越多,因此其训练函数如下所示。
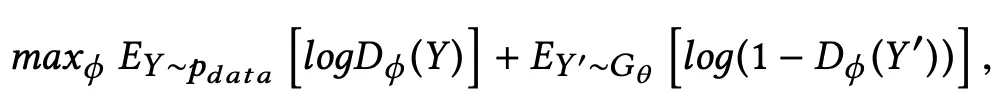
该函数不利于使用梯度上升法进行前反馈训练,因此将利用策略梯度的方式得出梯度,梯度公式如下所示。
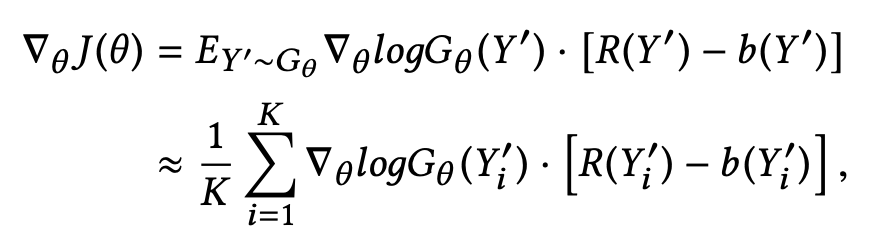
此外模型为了实现多任务训练的目的,利用 L1 正则对 MF 模型学习到的特征向量与 Seq2Seq 产生的特征向量进行正则化,最终该对抗 Seq2Seq 网络的损失函数定义如下所示。
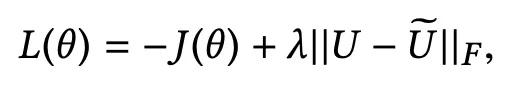
内容敏感型PMF模型
这部分模型与 2008 年在 NIPS 发表的 PMF 模型 [4] 基本一致。评价概率计算公式如下所示。
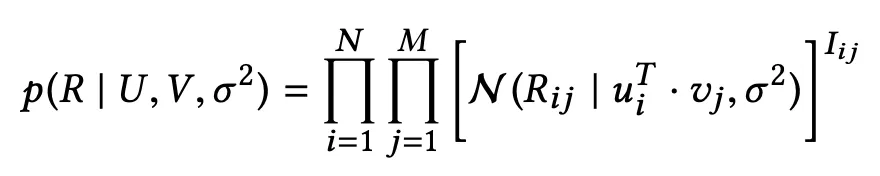
其中,
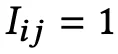 表示用户 i 对 item j 有评论,否则为 0。此外论文还定义了与用户和 item 的潜在特征向量的先验概率分布,公式如下。
表示用户 i 对 item j 有评论,否则为 0。此外论文还定义了与用户和 item 的潜在特征向量的先验概率分布,公式如下。
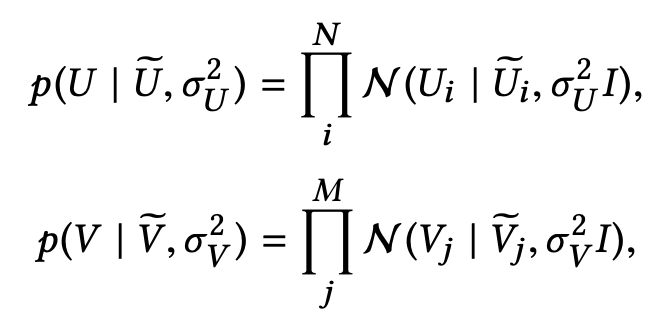
公式右侧的 U、V 分别为对抗 Seq2Seq 中生成的潜在特征向量。
优化方式
由于在内容敏感的 PMF 阶段,利用到了 Seq2Seq 部分生成的中间结果,因此无法用常见的随机梯度下降的方式同步进行参数优化。论文借鉴了经典的 EM 算法,保证部分参数不变的情况下进行最优化,反复迭代直至收敛的过程。
首先,先将 Seq2Seq 得到的用户与 Item 的潜在向量作为先验知识,关于 U、V 的后验分布概率可以定义如下。
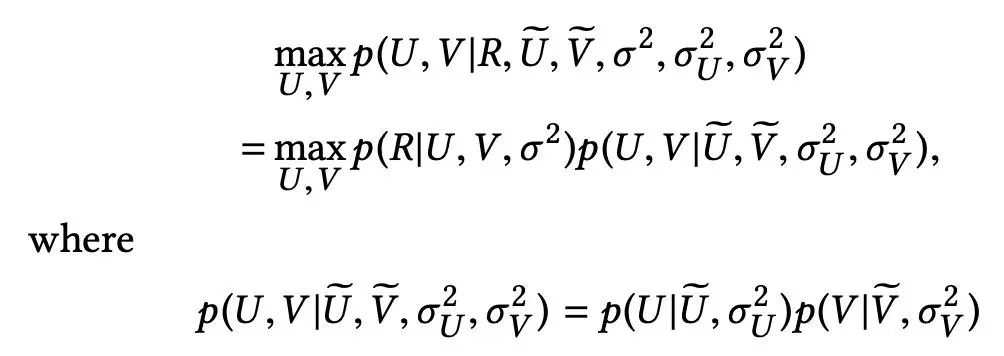
而相关的损失函数可已转化为如下公式。
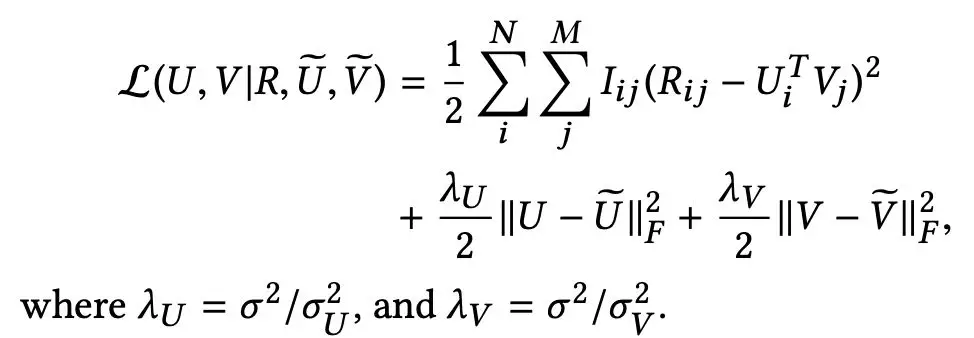
然后,将 U、V 固定对抗式 Seq2Seq 算法按照上述的损失函数定义,进行最优化,反复迭代直至收敛。整个模型的算法优化过程的伪代码如下图所示。

模型实验效果
论文使用均方误差(MSE)作为对预测评分的评价指标。对 Yelp 2013、Yelp 2014 等 5 个国际通用数据集进行试验,结果如下所示。
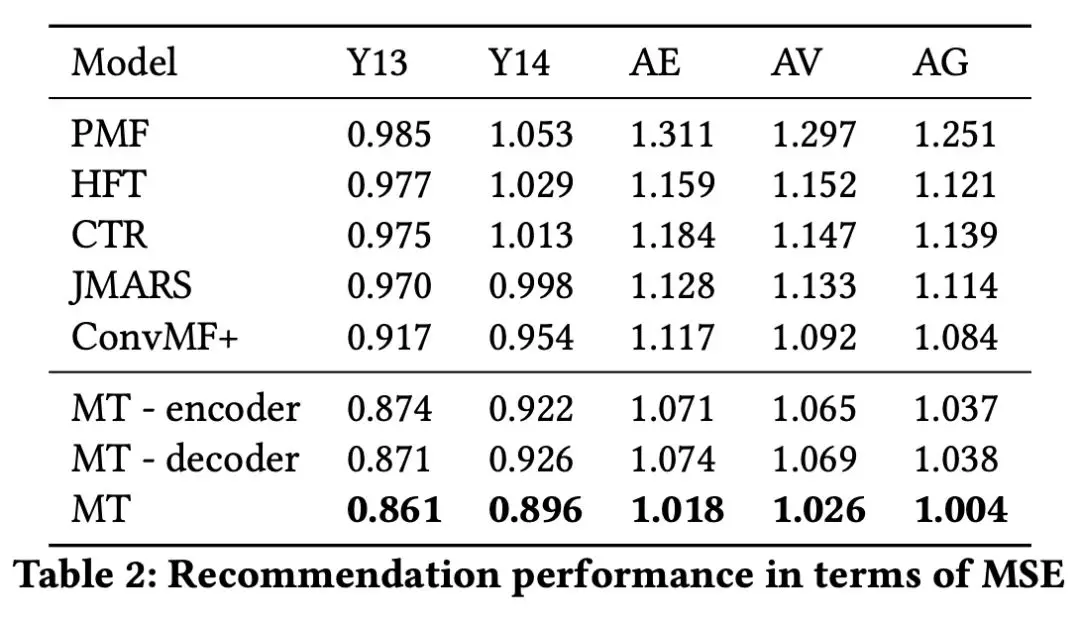
MT 为本论文所提出的的多任务学习的推荐算法模型,由实验结果所示,该算法模型的 MSE 的结果最多个数据集的结果中都表现最优。
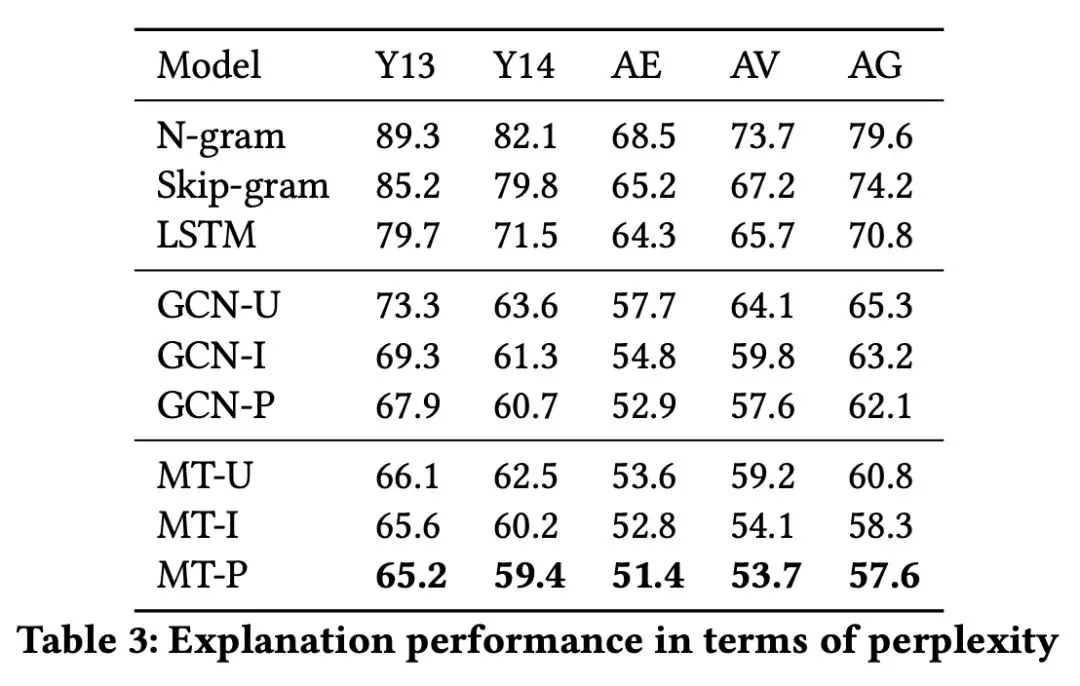
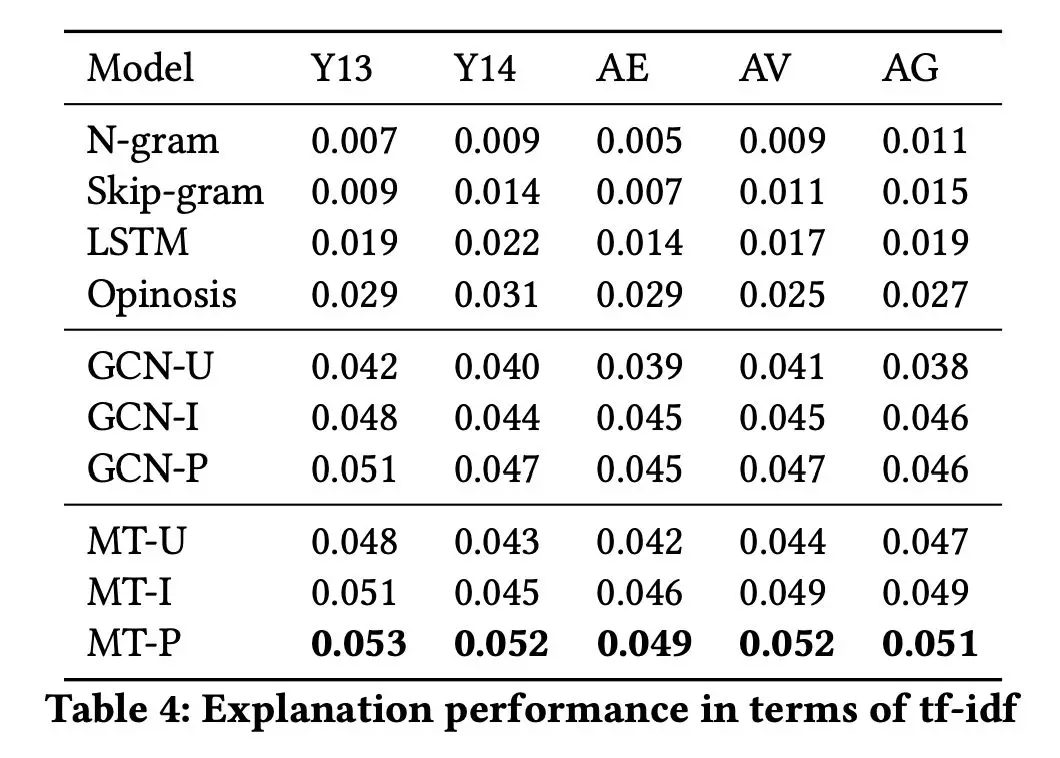
对于推荐系统的算法解释效果如何,最佳的评价方式就是线上与用户进行互动调研。但目前论文还没有这样做,论文采用了一种妥协的方式评价生成的评论质量如何。
利用 P erplexity [5] 的评价指标对比其他生成模型的生成效果以及 tf-idf 的相似性计算方式评价生成的评论与真实评论的近似性,结果如下所示,本论文模型生成的评论效果最佳。
论文评价
这篇论文发表于 2018 年的推荐系统顶级会议 RecSys,论文尝试用生成评论的方式解决推荐算法的解释合理性难题,并将预测评分率的效果达到了 state-of-the-art。评论生成的方式作为推荐解释的方式虽然存在争议,但不失为一条路径。
论文中涵盖了多种前沿领域的研究热点,包括对抗式网络、AutoEncoder、强化学习、多任务学习等等,是值得一看的优质应用论文。
参考文献
[1] Lu Y, Dong R, Smyth B. Why I like it: multi-task learning for recommendation
- 原文作者:知识铺
- 原文链接:https://geek.zshipu.com/post/%E4%BA%92%E8%81%94%E7%BD%91/%E7%9F%A5%E5%85%B6%E7%84%B6%E7%9F%A5%E5%85%B6%E6%89%80%E4%BB%A5%E7%84%B6%E5%9F%BA%E4%BA%8E%E5%A4%9A%E4%BB%BB%E5%8A%A1%E5%AD%A6%E4%B9%A0%E7%9A%84%E5%8F%AF%E8%A7%A3%E9%87%8A%E6%8E%A8%E8%8D%90%E7%B3%BB%E7%BB%9F/
- 版权声明:本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可,非商业转载请注明出处(作者,原文链接),商业转载请联系作者获得授权。
- 免责声明:本页面内容均来源于站内编辑发布,部分信息来源互联网,并不意味着本站赞同其观点或者证实其内容的真实性,如涉及版权等问题,请立即联系客服进行更改或删除,保证您的合法权益。转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。也可以邮件至 sblig@126.com


